Создание модели распознавания лиц с использованием глубокого обучения на языке Python
Переводчик Елена Борноволокова специально для Нетологии адаптировала статью Файзана Шайха о том, как создать модель распознавания лиц и в каких сферах ее можно применять.
Введение
За последние годы компьютерное зрение набрало популярность и выделилось в отдельное направление. Разработчики создают новые приложения, которыми пользуются по всему миру.
В этом направлении меня привлекает концепция открытого исходного кода. Даже технологические гиганты готовы делиться новыми открытиями и инновациями со всеми, чтобы технологии не оставались привилегией богатых.
Одна из таких технологий — распознавание лиц. При правильном и этичном использовании эта технология может применяться во многих сферах жизни.
В этой статье я покажу вам, как создать эффективный алгоритм распознавания лиц, используя инструменты с открытым исходным кодом. Прежде чем перейти к этой информации, хочу, чтобы вы подготовились и испытали вдохновение, посмотрев это видео:
Распознавание лиц: потенциальные сферы применения
Приведу несколько потенциальных сфер применения технологии распознавания лиц.
Распознавание лиц в соцсетях. Facebook заменил присвоение тегов изображениям вручную на автоматически генерируемые предложения тегов для каждого изображения, загружаемого на платформу. Facebook использует простой алгоритм распознавания лиц для анализа пикселей на изображении и сравнения его с соответствующими пользователями.
Распознавание лиц в сфере безопасности. Простой пример использования технологии распознавания лиц для защиты личных данных — разблокировка смартфона «по лицу». Такую технологию можно внедрить и в пропускную систему: человек смотрит в камеру, а она определяет разрешить ему войти или нет.
Распознавание лиц для подсчета количества людей. Технологию распознавания лиц можно использовать при подсчете количества людей, посещающих какое-либо мероприятие (например, конференцию или концерт). Вместо того чтобы вручную подсчитывать участников, мы устанавливаем камеру, которая может захватывать изображения лиц участников и выдавать общее количество посетителей. Это поможет автоматизировать процесс и сэкономить время.

Настройка системы: требования к аппаратному и программному обеспечению
Рассмотрим, как мы можем использовать технологию распознавания лиц, обратившись к доступным нам инструментам с открытым исходным кодом.
Я использовал следующие инструменты, которые рекомендую вам:
Шаг 1: Настройка аппаратного обеспечения
Проверьте, правильно ли настроена камера. С Ubuntu это сделать просто: посмотрите, опознано ли устройство операционной системой. Для этого выполните следующие шаги:
Шаг 2: Настройка программного обеспечения
Шаг 2.1: Установка Python
Код, указанный в данной статье, написан с использованием Python (версия 3.5). Для установки Python рекомендую использовать Anaconda – популярный дистрибутив Python для обработки и анализа данных.
Шаг 2.2: Установка OpenCV
OpenCV – библиотека с открытым кодом, которая предназначена для создания приложений компьютерного зрения. Установка OpenCV производится с помощью pip :
Шаг 2.3: Установите face_recognition API
Внедрение
После настройки системы переходим к внедрению. Для начала, мы создадим программу, а затем объясним, что сделали.
Пошаговое руководство
Создайте файл face_detector.py и затем скопируйте приведенный ниже код:
Затем запустите этот файл Python, напечатав:
Если все работает правильно, откроется новое окно с запущенным режимом распознавания лиц в реальном времени.
Подведем итоги и объясним, что сделал наш код:
Пример применения технологии распознавания лиц
На этом все самое интересное не заканчивается. Мы сделаем еще одну классную вещь: создадим полноценный пример применения на основе кода, приведенного выше. Внесем небольшие изменения в код, и все будет готово.
Предположим, что вы хотите создать автоматизированную систему с использованием видеокамеры для отслеживания, где спикер находится в данный момент времени. В зависимости от его положения, система поворачивает камеру так, что спикер всегда остается в центре кадра.
Первый шаг — создайте систему, которая идентифицирует человека или людей на видео и фокусируется на местонахождении спикера.
Разберем, как это сделать. В качестве примера я выбрал видео на YouTube с выступлением спикеров конференции «DataHack Summit 2017».
Сначала импортируем необходимые библиотеки:
Затем считываем видео и устанавливаем длину:
После этого создаем файл вывода с необходимым разрешением и скоростью передачи кадров, аналогичной той, что была в файле ввода.
Загружаем изображение спикера в качестве образца для распознания его на видео:
Закончив, запускаем цикл, который будет:
Распознавание лиц при помощи Python и OpenCV
В этой статье мы разберемся, что такое распознавание лиц и чем оно отличается от определения лиц на изображении. Мы кратко рассмотрим теорию распознавания лиц, а затем перейдем к написанию кода. В конце этой статьи вы сможете создать свою собственную программу распознавания лиц на изображениях, а также в прямом эфире с веб-камеры.
Содержание
Что такое обнаружение лиц?
Одной из основных задач компьютерного зрения является автоматическое обнаружение объекта без вмешательства человека. Например, определение человеческих лиц на изображении.
Лица людей отличаются друг от друга. Но в целом можно сказать, что всем им присущи определенные общие черты.
Существует много алгоритмов обнаружения лиц. Одним из старейших является алгоритм Виолы-Джонса. Он был предложен в 2001 году и применяется по сей день. Чуть позже мы тоже им воспользуемся. После прочтения данной статьи вы можете изучить его более подробно.
Обнаружение лиц обычно является первым шагом для решения более сложных задач, таких как распознавание лиц или верификация пользователя по лицу. Но оно может иметь и другие полезные применения.
Вероятно самым успешным использованием обнаружения лиц является фотосъемка. Когда вы фотографируете своих друзей, встроенный в вашу цифровую камеру алгоритм распознавания лиц определяет, где находятся их лица, и соответствующим образом регулирует фокус.
Что такое распознавание лиц?
Итак, в создании алгоритмов обнаружения лиц мы (люди) преуспели. А можно ли также распознавать, чьи это лица?
Распознавание лиц — это метод идентификации или подтверждения личности человека по его лицу. Существуют различные алгоритмы распознавания лиц, но их точность может различаться. Здесь мы собираемся описать распознавание лиц при помощи глубокого обучения.
Итак, давайте разберемся, как мы распознаем лица при помощи глубокого обучения. Для начала мы производим преобразование, или, иными словами, эмбеддинг (embedding), изображения лица в числовой вектор. Это также называется глубоким метрическим обучением.
Для облегчения понимания давайте разобьем весь процесс на три простых шага:
Обнаружение лиц
Наша первая задача — это обнаружение лиц на изображении или в видеопотоке. Далее, когда мы знаем точное местоположение или координаты лица, мы берем это лицо для дальнейшей обработки.
Извлечение признаков
Вырезав лицо из изображения, мы должны извлечь из него характерные черты. Для этого мы будем использовать процедуру под названием эмбеддинг.
Нейронная сеть принимает на вход изображение, а на выходе возвращает числовой вектор, характеризующий основные признаки данного лица. (Более подробно об этом рассказано, например, в нашей серии статей про сверточные нейронные сети — прим. переводчика). В машинном обучении данный вектор как раз и называется эмбеддингом.
Теперь давайте разберемся, как это помогает в распознавании лиц разных людей.

Во время обучения нейронная сеть учится выдавать близкие векторы для лиц, которые выглядят похожими друг на друга.
Например, если у вас есть несколько изображений вашего лица в разные моменты времени, то естественно, что некоторые черты лица могут меняться, но все же незначительно. Таким образом, векторы этих изображений будут очень близки в векторном пространстве. Чтобы получить общее представление об этом, взгляните на график:
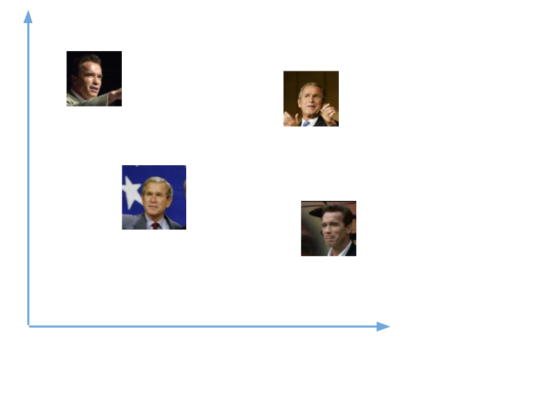
Чтобы определять лица одного и того же человека, сеть будет учиться выводить векторы, находящиеся рядом в векторном пространстве. После обучения эти векторы трансформируются следующим образом:
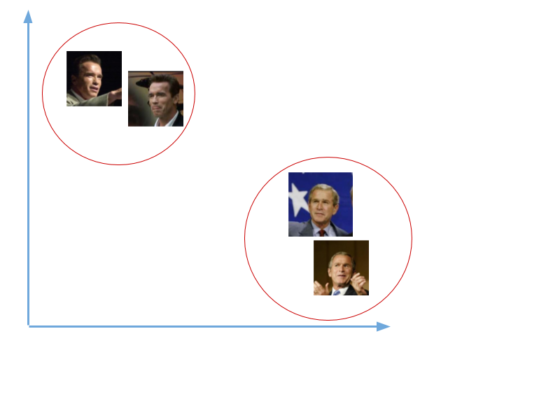
Здесь мы не будем заниматься обучением подобной сети. Это требует значительных вычислительных мощностей и большого объема размеченных данных. Вместо этого мы используем уже предобученную Дэвисом Кингом нейронную сеть. Она обучалась приблизительно на 3000000 изображений. Эта сеть выдает вектор длиной 128 чисел, который и определяет основные черты лица.
Познакомившись с принципами работы подобных сетей, давайте посмотрим, как мы будем использовать такую сеть для наших собственных данных.
Мы передадим все наши изображения в эту предобученную сеть, получим соответствующие вектора (эмбеддинги) и затем сохраним их в файл для следующего шага.
Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
Сравнение лиц
Теперь, когда у нас есть вектор (эмбеддинг) для каждого лица из нашей базы данных, нам нужно научиться распознавать лица из новых изображений. Таким образом, нам нужно, как и раньше, вычислить вектор для нового лица, а затем сравнить его с уже имеющимися векторами. Мы сможем распознать лицо, если оно похоже на одно из лиц, уже имеющихся в нашей базе данных. Это означает, что их вектора будут расположены вблизи друг от друга, как показано на примере ниже:
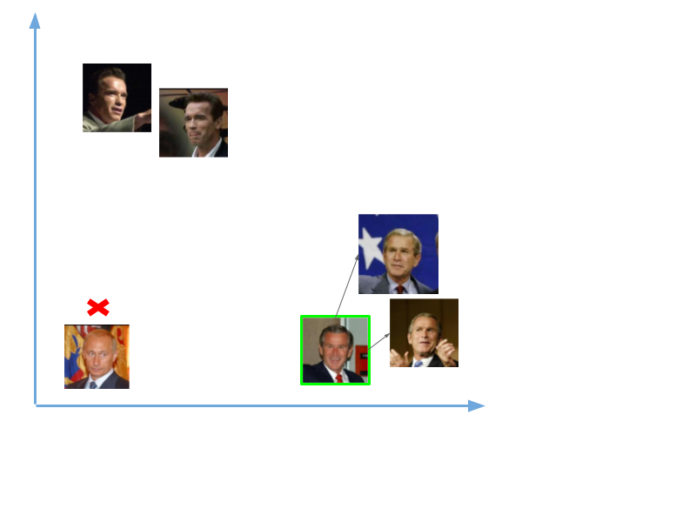
Итак, мы передали в сеть две фотографии, одна Владимира Путина, другая Джорджа Буша. Для изображений Буша у нас были вектора (эмбеддинги), а для Путина ничего не было. Таким образом, когда мы сравнили эмбеддинг нового изображения Буша, он был близок с уже имеющимися векторам,и и мы распознали его. А вот изображений Путина в нашей базе не было, поэтому распознать его не удалось.
Что такое OpenCV?
В области искусственного интеллекта задачи компьютерного зрения — одни из самых интересных и сложных.
Компьютерное зрение работает как мост между компьютерным программным обеспечением и визуальной картиной вокруг нас. Оно дает ПО возможность понимать и изучать все видимое в окружающей среде.
Например, на основе цвета, размера и формы плода мы определяем разновидность определенного фрукта. Эта задача может быть очень проста для человеческого разума, однако в контексте компьютерного зрения все выглядит иначе.
Сначала мы собираем данные, затем выполняем определенные действия по их обработке, а потом многократно обучаем модель, как ей распознавать сорт фрукта по размеру, форме и цвету его плода.
В настоящее время существуют различные пакеты для выполнения задач машинного обучения, глубокого обучения и компьютерного зрения. И безусловно, модуль, отвечающий за компьютерное зрение, проработан лучше других.
OpenCV — это библиотека с открытым программным кодом. Она поддерживает различные языки программирования, например R и Python. Работать она может на многих платформах, в частности — на Windows, Linux и MacOS.
Основные преимущества OpenCV :
Установка
Здесь мы будем рассматривать установку OpenCV только для Python. Мы можем установить ее при помощи менеджеров pip или conda (в случае, если у нас установлен пакет Anaconda).
1. При помощи pip
При помощи pip процесс установки может быть выполнен с использованием следующей команды:
2. Anaconda
Если вы используете Anaconda, то выполните следующую команду в окружении Anaconda:
Распознавание лиц с использованием Python
В этой части мы реализуем распознавание лиц при помощи Python и OpenCV. Для начала посмотрим, какие библиотеки нам потребуются и как их установить:
OpenCV — это библиотека обработки изображений и видео, которая используется для их анализа. Ее применяют для обнаружения лиц, считывания номерных знаков, редактирования фотографий, расширенного роботизированного зрения, оптического распознавания символов и многого другого.
Для установки OpenCV наберите в командной строке:
Мы перепробовали множество способов установки dlib под WIndows и простейший способ это сделать — при помощи Anaconda. Поэтому для начала установите Anaconda (вот здесь подробно рассказано, как это делается). Затем введите в терминале следующую команду:
Далее, для установки библиотеки face_recognition наберите в командной строке следующее:
Теперь, когда все необходимые модули установлены, приступим к написанию кода. Нам нужно будет создать три файла.
Первый файл будет принимать датасет с изображениями и выдавать эмбеддинг для каждого лица. Эти эмбеддинги будут записываться во второй файл. В третьем файле мы будем сравнивать лица с уже существующими изображениями. А затем мы сделаем тоже самое в стриме с веб-камеры.
Извлечение признаков лица
Для начала вам нужно достать датасет с лицами или создать свой собственный. Главное, убедитесь, что все изображения находятся в папках, причем в каждой папке должны быть фотографии одного и того же человека.
Затем разместите датасет в вашей рабочей директории, то есть там, где выбудете создавать собственные файлы.
Распознавание лиц во время прямой трансляции веб-камеры
Вот код для распознавания лиц из прямой трансляции веб-камеры:
Распознавание лиц на изображениях
Код для обнаружения и распознавания лиц на изображениях почти аналогичен тому, что вы видели выше. Убедитесь в этом сами:
Результат:


На этом наша статья подошла к концу. Мы надеемся, что вы получили общее представление о задачах распознавания лиц и способах их решения.
Создание модели распознавания лиц с использованием глубокого обучения на языке Python
Адаптировали статью Файзана Шайха о том, как создать модель распознавания лиц и в каких сферах её можно применять.

За последние годы компьютерное зрение набрало популярность и выделилось в отдельное направление. Разработчики создают новые приложения, которыми пользуются по всему миру.
В этом направлении привлекает концепция открытого исходного кода. Даже технологические гиганты готовы делиться новыми открытиями и инновациями со всеми, чтобы технологии не оставались привилегией богатых.
Одна из таких технологий — распознавание лиц. При правильном и этичном использовании эта технология может применяться во многих сферах жизни.
В этой статье покажем, как создать эффективный алгоритм распознавания лиц, используя инструменты с открытым исходным кодом. Прежде чем перейти к этой информации, хотим, чтобы вы подготовились и испытали вдохновение, посмотрев это видео:
Распознавание лиц: потенциальные сферы применения
Приведу несколько потенциальных сфер применения технологии распознавания лиц.
Распознавание лиц в соцсетях. Facebook заменил присвоение тегов изображениям вручную на автоматически генерируемые предложения тегов для каждого изображения, загружаемого на платформу. Facebook использует простой алгоритм распознавания лиц для анализа пикселей на изображении и сравнения его с соответствующими пользователями.
Распознавание лиц в сфере безопасности. Простой пример использования технологии распознавания лиц для защиты личных данных — разблокировка смартфона «по лицу». Такую технологию можно внедрить и в пропускную систему: человек смотрит в камеру, а она определяет, разрешить ему войти или нет.
Поиск лиц на изображении с использованием OpenCV в Python

Обнаружение объектов — это компьютерная технология, связанная с компьютерным зрением и обработкой изображений, которая занимается обнаружением экземпляров семантических объектов определенного класса, например, человеческие лица, автомобили, фрукты и т. д., в цифровых изображениях и видео.
После этого мы погрузимся в использование детекторов Single Shot Multibox (или коротко SSD), которые представляют собой метод обнаружения объектов на изображениях с использованием одной глубокой нейронной сети.
Распознавание лиц с помощью каскадов Хаара
Каскадные классификаторы Хаара на основе функций — это подход, основанный на машинном обучении, при котором каскадная функция обучается на основе большого количества положительных и отрицательных изображений. Затем он используется для обнаружения объектов на других изображениях. Преимущество каскадных классификаторов Хаара в том, что вы можете создать классификатор любого объекта, который захотите, OpenCV уже предоставил вам некоторые параметры классификатора, поэтому вам не нужно собирать какие-либо данные для обучения.
Для начала установите нужные нам пакеты:
Хорошо, создайте новый файл Python и продолжайте, для начала, импортируя OpenCV:
Вам понадобится образец изображения для тестирования, убедитесь, что на нем есть четкие лицевые стороны. Я буду использовать стоковое изображение, которое содержит двух очень милых детишек:
Функция imread() загружает изображение из указанного файла и возвращает его как N-мерный массив numpy.
Прежде чем мы обнаружим лица на изображении, нужно преобразовать изображение в оттенки серого, потому что функция, которую мы собираемся использовать для обнаружения лиц, ожидает изображение в оттенках серого:
Давайте теперь обнаружим все лица на изображении:
Функция detectMultiScale() принимает изображение в качестве параметра и обнаруживает объекты разных размеров в виде списка прямоугольников, давайте нарисуем эти прямоугольники на изображении:
Наконец, сохраним новое изображение:
Вот что у меня получилось: 
Довольно круто, не правда ли? Не стесняйтесь использовать другие классификаторы объектов, другие изображения и, что еще интереснее, используйте свою веб-камеру! Вот код для этого:
Распознавание лиц с помощью SSD
Как видите, предыдущий метод не так уж и сложен. К сожалению, он устарел и сегодня, в реальном мире, редко когда используется. Однако, нейронные сети всегда приходят на помощь, и, к счастью для нас, OpenCV содержит замечательный для нас модуль dnn в пакете cv2, который позволяет находить лица, используя предварительно обученные модели глубокого обучения.
Мы будем использовать то же изображение:
Чтобы передать загруженное изображение в нейронную сеть, его нужно предварительно подготовить. В частности, нам нужно изменить размер изображения до размеров (300, 300) и выполнить вычитание среднего, поскольку сеть так обучена:
Будем использовать объект blob в качестве входа в сеть и выполнить прямую связь, чтобы получить обнаруженные лица:
Теперь выходной объект содержит все обнаруженные объекты (в данном случае лица), давайте переберем этот массив и нарисуем все лица на изображении с достоверностью более 50%:
После того, как мы убедились в достоверности модели обнаруженного объекта, получаем охватывающий прямоугольник и умножаем его на ширину и высоту исходного изображения для вычисления правильных координат прямоугольника, потому что, как вы помните, ранее изменялся размер изображения до (300, 300), поэтому и на выходе также должно быть значение от 0 до 300.
В этом случае мы не только нарисовали окружающие прямоугольники, но и написали текст с указанием достоверности в процентах, давайте покажем и сохраним новое изображение:
Вот получившееся изображение: 
Замечательно, этот метод намного лучше и точнее, но он может быть хуже с точки зрения FPS (Кадровая частота એ ), если вы прогнозируете лица в реальном времени, поскольку он не так быстр, как каскадный метод Хаара.
Существует множество реальных приложений для обнаружения лиц, например, мы использовали обнаружение лиц для их размытия на изображениях и в видео в реальном времени, используя OpenCV!
Руководство по распознаванию лиц в Python
Дата публикации Apr 5, 2019

В этом руководстве мы увидим, как создать и запустить алгоритм обнаружения лиц в Python с использованием OpenCV и Dlib. Мы также добавим некоторые функции для одновременного обнаружения глаз и рта на нескольких лицах. В этой статье будут рассмотрены самые основные реализации распознавания лиц, в том числе каскадные классификаторы, окна HOG и Deep Learning CNN.
Мы рассмотрим обнаружение лица с помощью:
Эта статья была первоначально опубликована в моем личном блоге:https://maelfabien.github.io/tutorials/face-detection/#
Github-репозиторий этой статьи (и все остальные из моего блога) можно найти здесь:
maelfabien / Machine_Learning_Tutorials
github.com
Введение
Мы будем использовать OpenCV, библиотеку с открытым исходным кодом для компьютерного зрения, написанную на C / C ++, которая имеет интерфейсы на C ++, Python и Java. Он поддерживает Windows, Linux, MacOS, iOS и Android. Некоторые из наших работ также потребуют использования Dlib, современного инструментария C ++, содержащего алгоритмы машинного обучения и инструменты для создания сложного программного обеспечения.
Требования
Первым шагом является установка OpenCV и Dlib. Запустите следующую команду:
В зависимости от вашей версии файл будет установлен здесь:
Если у вас возникли проблемы с Dlib, проверьтеЭта статья,
Импорт и модели пути
Мы создадим новый файл Jupyter notebook / python и начнем с:
I. Каскадные классификаторы
Сначала рассмотрим каскадные классификаторы.
I.1. теория
Каскадный классификатор, или, в частности, каскад повышенных классификаторов, работающих с хаароподобными функциями, представляет собой особый случай ансамблевого обучения, называемый повышением. Как правило, опирается наAdaBoostклассификаторы (и другие модели, такие как Real Adaboost, Gentle Adaboost или Logitboost).
Каскадные классификаторы обучаются на нескольких сотнях изображений изображений, которые содержат объект, который мы хотим обнаружить, и других изображениях, которые не содержат этих изображений.
Как мы можем определить, есть ли там лицо или нет? Существует алгоритм, называемый средой обнаружения объектов Viola – Jones, который включает в себя все этапы, необходимые для обнаружения живого лица:
Оригиналбумагабыл опубликован в 2001 году.
I.1.a. Выбор Хаара
Есть некоторые общие черты, которые мы находим на самых обычных человеческих лицах:
Характеристики называются Haar Features. Процесс извлечения функции будет выглядеть так:

В этом примере первый признак измеряет разницу в интенсивности между областью глаз и областью через верхние щеки. Значение объекта просто вычисляется путем суммирования пикселей в черной области и вычитания пикселей в белой области.

Затем мы применяем этот прямоугольник как сверточное ядро по всему нашему изображению. Чтобы быть исчерпывающим, мы должны применить все возможные размеры и положения каждого ядра. Простые 24 * 24 изображения обычно дают более 160 000 объектов, каждое из которых состоит из суммы / вычитания значений пикселей. В вычислительном отношении это было бы невозможно для живого обнаружения лица. Итак, как мы можем ускорить этот процесс?

Существует несколько типов прямоугольников, которые можно применять для извлечения объектов Haar. Согласно оригинальной статье:

Теперь, когда функции выбраны, мы применяем их к набору обучающих изображений, используя классификацию Adaboost, которая объединяет набор слабых классификаторов для создания точной модели ансамбля. Благодаря 200 функциям (вместо 160 000 изначально) достигается точность 95%. Авторы статьи выбрали 6’000 функций.
I.1.b Цельное изображение
Вычисление элементов прямоугольника в стиле сверточного ядра может быть долгим, очень долгим. По этой причине авторы, Виола и Джонс, предложили промежуточное представление для изображения: целостное изображение. Роль интегрального изображения заключается в том, чтобы просто вычислить любую прямоугольную сумму, используя только четыре значения. Посмотрим, как это работает!
Предположим, мы хотим определить объекты прямоугольника в данном пикселе с координатами (x, y). Затем выполняется интегральное изображение пикселя в сумме пикселей выше и слева от данного пикселя.

Когда вы вычисляете целое целое изображение, возникает рецидив формы, который требует только одного прохода исходного изображения. Действительно, мы можем определить следующую пару повторений:

Чем это может быть полезно? Хорошо, рассмотрим область D, для которой мы хотели бы оценить сумму пикселей. Мы определили 3 других региона: A, B и C.
Следовательно, сумма пикселей в области D может быть просто вычислена как: 4 + 1 (2 + 3).
И за один проход мы вычислили значение внутри прямоугольника, используя только 4 ссылки на массив.


I.1c. Изучение функции классификации с Adaboost
Учитывая набор помеченных тренировочных образов (положительных или отрицательных), Adaboost используется для:
Поскольку предполагается, что большинство функций из 160 000 не имеют никакого значения, слабый алгоритм обучения, на основе которого мы строим улучшающую модель, предназначен для выбора одного прямоугольника, который разделяет лучшие отрицательные и положительные примеры.
I.1.d. Каскадный классификатор
Ключевая идея состоит в том, чтобы отклонить подокна, которые не содержат граней, при определении областей, которые имеют. Поскольку задача состоит в том, чтобы правильно идентифицировать лицо, мы хотим минимизировать количество ложных отрицательных результатов, то есть подокна, которые содержат лицо и не были идентифицированы как таковые.
Ряд классификаторов применяется к каждому подокну. Эти классификаторы являются простыми деревьями решений:
Любой отрицательный результат в некоторой точке приводит к отклонению подокна как потенциально содержащего лицо. Первоначальный классификатор исключает большинство отрицательных примеров при низких вычислительных затратах, а следующие классификаторы устраняют дополнительные отрицательные примеры, но требуют больших вычислительных усилий.

Классификаторы обучаются с использованием Adaboost и настройкой порога, чтобы минимизировать ложную оценку. При обучении такой модели переменными являются следующие:
К счастью, в OpenCV вся эта модель уже прошла обучение по распознаванию лиц.
Если вы хотите узнать больше о методах повышения, я предлагаю вам проверить мою статью наAdaBoost,
I.2. импорт
После определения мы объявим каскадные классификаторы следующим образом:
I.3. Определить лицо на изображении
Перед реализацией алгоритма распознавания лиц в режиме реального времени, давайте попробуем простую версию изображения. Мы можем начать с загрузки тестового изображения:

Затем мы обнаруживаем лицо и добавляем вокруг него прямоугольник:
Вот список наиболее распространенных параметров detectMultiScale функция:
Наконец, отобразите результат:

Распознавание лиц хорошо работает на нашем тестовом изображении. Давайте перейдем к реальному времени сейчас!
I.4. Распознавание лиц в реальном времени
Давайте перейдем к реализации Python для распознавания лиц в реальном времени. Первым шагом является запуск камеры и захват видео. Затем мы преобразуем изображение в изображение в оттенках серого. Это используется для уменьшения размера входного изображения. Действительно, вместо 3 точек на пиксель, описывающих красный, зеленый, синий, мы применяем простое линейное преобразование:

Это реализовано по умолчанию в OpenCV.
Теперь мы будем использовать faceCascade Переменная определите выше, которая содержит предварительно обученный алгоритм, и примените его к изображению серой шкалы.
Для каждого обнаруженного лица мы нарисуем прямоугольник вокруг лица:
Для каждого обнаруженного рта нарисуйте вокруг него прямоугольник:
Для каждого обнаруженного глаза нарисуйте вокруг него прямоугольник:
Затем подсчитайте общее количество лиц и отобразите общее изображение:
И реализовать вариант выхода, когда мы хотим остановить камеру, нажав q :
Наконец, когда все будет сделано, отпустите захват и уничтожьте все окна. Существуют некоторые проблемы, связанные с уничтожением окон на Mac, которые могут потребовать позже удаления Python из диспетчера активности.
В.5. Завершение
I.6. Полученные результаты
Я сделал быстрыйYouTubeиллюстрация алгоритма распознавания лиц.
II. Гистограмма ориентированных градиентов (HOG) в Dlib
Второй наиболее популярный инструмент для распознавания лиц предлагается Dlib и использует концепцию, называемую Гистограмма ориентированных градиентов (HOG). Это реализация оригиналабумага Далала и Триггса,
II.1. теория
В оригинальной статье процесс был реализован для обнаружения человеческого тела, и цепочка обнаружения была следующей:

II.1.a. предварительная обработка
Прежде всего, входные изображения должны быть одинакового размера (кадрировать и масштабировать изображения). Для патчей, которые мы будем применять, требуется соотношение сторон 1: 2, поэтому размеры входных изображений могут быть 64×128 или 100×200 например.
II.1.b. Вычислить градиентные изображения
Первым шагом является вычисление горизонтального и вертикального градиентов изображения с применением следующих ядер:

Градиент изображения обычно удаляет ненужную информацию.
Градиент изображения, который мы рассматривали выше, можно найти в Python следующим образом:
И нарисуйте картинку:

Мы не обрабатывали изображение ранее, хотя.
II.1.c. Вычислить боров
Затем изображение делится на 8×8 ячеек, чтобы обеспечить компактное представление и сделать наш HOG более устойчивым к шуму. Затем мы вычисляем HOG для каждой из этих ячеек.
Чтобы оценить направление градиента внутри области, мы просто строим гистограмму среди 64 значений направлений градиента (8×8) и их величины (еще 64 значения) внутри каждой области. Категории гистограммы соответствуют углам градиента от 0 до 180 °. Всего 9 категорий: 0 °, 20 °, 40 °… 160 °.
Код выше дал нам 2 информации:
Когда мы строим HOG, есть 3 случая:


HOG выглядит так для каждой ячейки 8×8:

II.1.d. Блок нормализации
II.1.e. Блок нормализации
Наконец, все векторы 36×1 объединяются в большой вектор. И мы сделали! У нас есть вектор признаков, по которому мы можем обучить мягкий классификатор SVM (C = 0,01).
II.2. Определить лицо на изображении
Реализация довольно проста:

II.3. Распознавание лиц в реальном времени
Как и ранее, алгоритм довольно прост в реализации. Мы также реализуем более легкую версию, обнаруживая только лицо Dlib также позволяет легко определять ключевые точки лица, но это уже другая тема.
III. Сверточная нейронная сеть в Dlib
Этот последний метод основан на сверточных нейронных сетях (CNN). Он также реализуетбумагана Max-Margin Object Detection (MMOD) для улучшения результатов.
III.1. Немного теории
В предыдущих подходах большая часть работы заключалась в том, чтобы выбрать фильтры для создания функций, чтобы извлечь как можно больше информации из изображения. С ростом глубокого обучения и большей вычислительной мощности эта работа теперь может быть автоматизирована. Название CNN происходит от того факта, что мы объединяем начальный ввод изображения с набором фильтров. Параметром, который нужно выбрать, остается количество применяемых фильтров и размерность фильтров. Размер фильтра называется длиной шага. Типичные значения для шага лежат между 2 и 5.

Выходные данные CNN в этом конкретном случае представляют собой двоичную классификацию, которая принимает значение 1, если есть грань, 0 в противном случае.
III.2. Определить лицо на изображении
Некоторые элементы изменяются в реализации.
Тогда, очень похоже на то, что мы сделали до сих пор:

III.3. Распознавание лиц в реальном времени
Наконец, мы реализуем версию распознавания лиц CNN в режиме реального времени:
Внутривенно Какой выбрать?
Сложный вопрос, но мы просто пройдемся по двум важным метрикам:
С точки зрения скорости, HoG кажется самым быстрым алгоритмом, за которым следует классификатор Haar Cascade и CNN.
Тем не менее, CNN в Dlib, как правило, являются наиболее точным алгоритмом. HoG работают довольно хорошо, но есть некоторые проблемы с распознаванием маленьких лиц. Классификаторы HaarCascade работают так же хорошо, как и HoG.
Я лично использовал главным образом HoG в своих личных проектах из-за его скорости обнаружения живого лица.
ВыводНадеюсь, вам понравился этот краткий учебник по OpenCV и Dlib по распознаванию лиц. Не стесняйтесь оставлять комментарии, если у вас есть какие-либо вопросы / замечания.