Как перекодировать 1251 в UTF-8
Возникла задача перекодировать файлы сайта в формат UTF-8, а до этого данные файлы были созданы в кодировке WINDOWS-1251.
Вроде бы задача тривиальная — берем любой кодировщик и кодируем из widows-1251 в utf-8, но не тут то было, так можно делать если у нас десяток файлов.
А если файлов тысяча? Да и еще не скопом, а каждая группа в своей подкатегории!

Сразу в голову приходит идея — берем пакетный перекодировщик файлов и кодируем одним мановением мыши.
Кстати хочу заметить файлы у меня лежали на виртуальном сервере, и диск с файлами был подключен как обычный сетевой диск. Т.е. без всяких фтп и прочего, хотя конечно все это есть.
И так, необходим конвертер для пакетной кодировки в UTF.
И пакетной по-настоящему, а не выбрали кучу файлов и кодируем, чтобы можно было добавлять начальную директорию, а файлы кодировались рекурсивно.
После тщательных поисков было найдено решение!
Есть замечательный бесплатный конвертер для пакетного конвертирования в UTF — UTFCast Express — скачать конвертер UTFCast Express.
Он позволяет легко и быстро в автоматическом режиме перекодировать каталог и все файлы в подкаталогах. Но у него есть небольшая особенность! Так как версия Экспресс бесплатная — то она не имеет опции конвертировать в UTF-8 без BOM (BOM — Byte Order Mark, служит для идентификации кодировок UTF)
Недостаток результата конвертирования такой, что ваши PHP скрипты скорее всего не будут работать! А вот для решения этой проблемы необходимо применить вторую программку — скачать utf8-bom-remover.exe — UTF-8 BOM Remover
Эта тоже замечательная программа — прекрасно справляется с удалением BOM в UTF файлах. А главное рекурсивно все содержимое каталога и подкаталогов!
Вот такой связкой можно решить такой важный вопрос.
До этого я пересмотрел программы:
Smart Recoder 1.6.2b — не работает с UTF-8
TEA 26.2.0, TEA 27.0.1 — крутой редактор, но я не понял как его можно применить для этих целей, хотя некоторые пишут что можно
Encoding Master 1.63 — можете попробовать, но при добавлении моей директории он подвисал
Notepad++ (NPP) — классный, гибкий редактор, но как таковой рекурсивной простой и удобной перекодировки нет, но можно легко убирать BOM
AkelPad — можно вручную сохранять в UTF-8 без BOM
коммандер FAR с плагином FarTrans — при обработке 1010 файлов php плагин вылетал в течении 3-х секунд, пробовал несколько раз
Ansi2Uni — классный маленький конвертер, но с несовсем рекурсией
Russian Anywhere 4.62 — навороченный конвертер, но как-то не пошел
Kaboom — вроде было все что нужно, вот только с рекурсией не удалось
UTF8_convert — минимум кнопок, но нет возможности выключать BOM
ABConverter — не работает с UTF
Если есть желание и возможности заплатить 30$, то рекомендую купить платную версию UTFCast Professional очень мощный, гибкий и удобный конвертер (по крайней мере мне так показалось)
Как изменить кодировку текстового файла на UTF-8 или Windows 1251
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню « Файл – Сохранить как ».
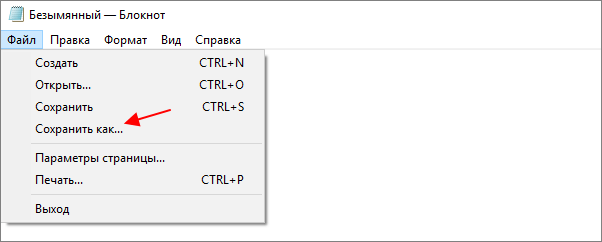
В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку « Сохранить ».
К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню « Кодировки – Кириллица » и выбрать нужный вариант.
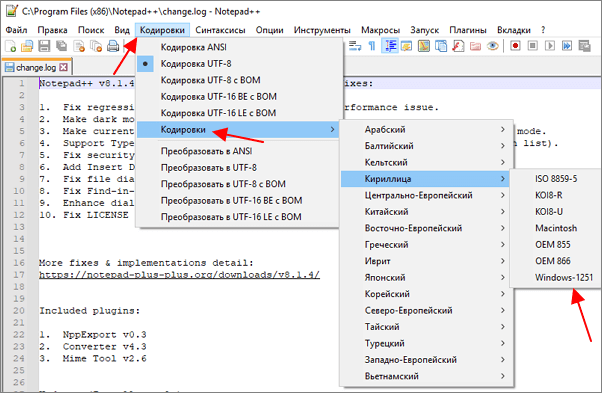
После открытия текста можно изменить его кодировку. Для этого нужно открыть меню « Кодировки » и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.
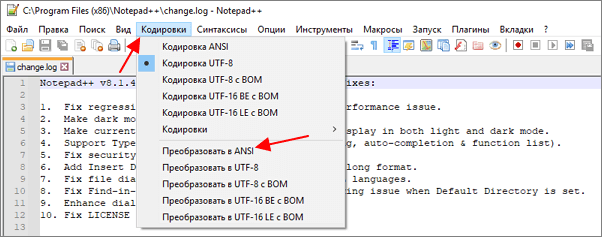
После преобразования файл нужно сохранить с помощью меню « Файл – Сохранить » или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню « Файл – Открыть ».
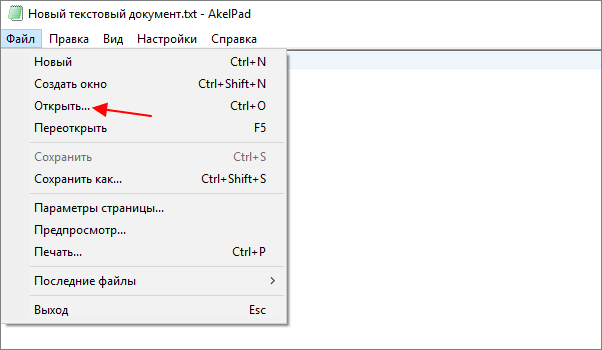
В открывшемся окне нужно выделить текстовый файл, снять отметку « Автовыбор » и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.
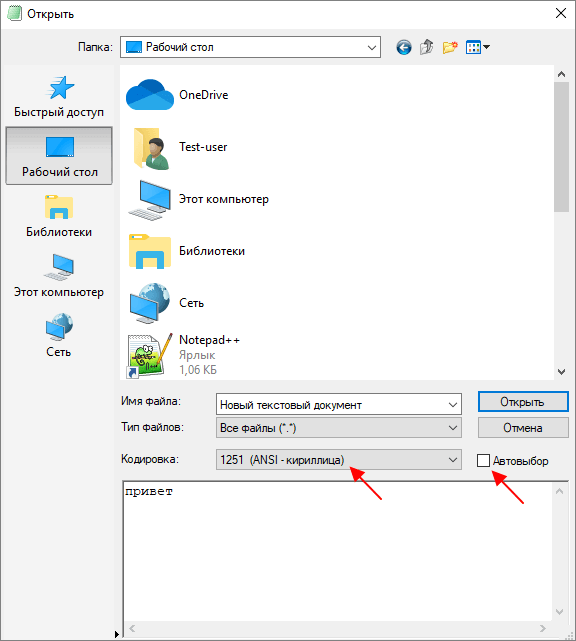
Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню « Файл – Сохранить как » и сохранить документ с указанием новой схемы кодирования.
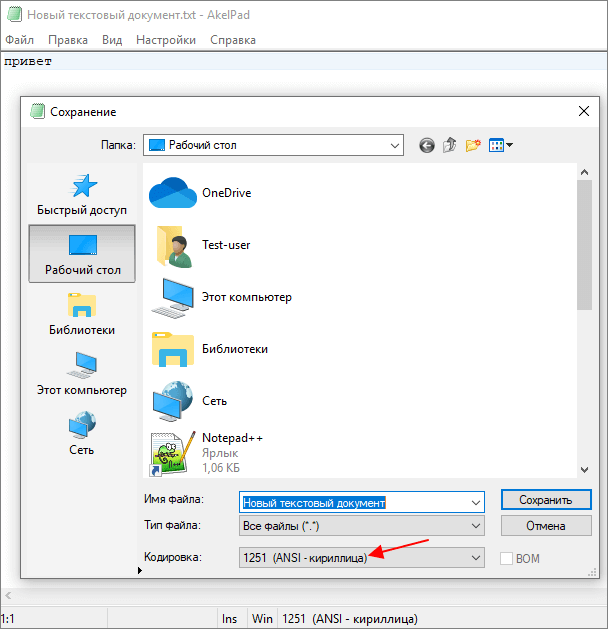
В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Заметки Лёвика
web программирование, администрирование и всякая всячина, которая может оказаться полезной
При помощи функции php iconv (строго говоря, это не совсем функция PHP, она использует стороннюю библиотеку (есть iconv.dll и php_iconv.dll или iconv.so), которой может не быть на хостинге) легко преобразовать кодировку (например, из windows-1251 в utf-8 и наоборот:
Если не работает iconv
Т.е. чтобы преобразовать текст из кодировки windows-1251 в UTF-8 следует выполнить:
mb_convert_encoding($s,»UTF-8″,»windows-1251″);
iconv array для массива
Метки: iconv
Опубликовано Пятница, Октябрь 21, 2011 в 15:02 в следующих категориях: Без рубрики. Вы можете подписаться на комментарии к этому сообщению через RSS 2.0. Вы можете оставить комментарий. Пинг отключен.
Автор будет признателен, если Вы поделитесь ссылкой на статью, которая Вам помогла:
BB-код (для вставки на форум)
html-код (для вставки в ЖЖ, WP, blogger и на страницы сайта)
ссылка (для отправки по почте)
Как быть с запросом select к базе mssql не понимает кирилицу
“select
[Название]
,[номер]
, [Removed]
from imdb.dbo. Оконечное оборудование “;
Следует привести столбцы (или всю базу данных сразу) к соответствующему сравнению (кодировке)
ALTER DATABASE COLLATE Cyrillic_General_CI_AS
Или использовать Nvarchar
declare @test TABLE
(
Col1 varchar(40),
Col2 varchar(40),
Col3 nvarchar(40),
Col4 nvarchar(40)
)
INSERT INTO @test VALUES
(‘иытание’,N’иытание’,’иытание’,N’иытание’)
SELECT * FROM @test
Если изменяю версию php 5.6 то не перекодируется. Не подскажете?
Как из стоки windows-1251 получить строку UTF-8 на C#?

может так попробовать?

как вариант можно попробовать сериализовать в json с помощью специально для этого реализованными инструментами, например: newtonsoft json.
еще у WebClient`а есть свойство Encoding. Можно попробовать разные варианты.

Из этого становится виден сценарий:
1. Считать файл байтов, где символы кодируются в windows-1251.
2. Преобразовать в UTF-16
3. Выполнить над строками различные необходимые действия.
4. Сохранить результат с преобразованием в набор байт, где символы представленны как UTF-8.
И пример кода:
1-2. Построчное чтение из файла с windows-1251
4. Помещаем в тело запроса набор байт, где символы в UTF-8
iconv
(PHP 4 >= 4.0.5, PHP 5, PHP 7, PHP 8)
iconv — Преобразование строки в требуемую кодировку
Описание
Список параметров
Кодировка входной строки.
Требуемая на выходе кодировка.
Строка, которую необходимо преобразовать.
Возвращаемые значения
Возвращает преобразованную строку или false в случае возникновения ошибки.
Примеры
Пример #1 Пример использования iconv()
Результатом выполнения данного примера будет что-то подобное:
User Contributed Notes 39 notes
The «//ignore» option doesn’t work with recent versions of the iconv library. So if you’re having trouble with that option, you aren’t alone.
That means you can’t currently use this function to filter invalid characters. Instead it silently fails and returns an empty string (or you’ll get a notice but only if you have E_NOTICE enabled).
[UPDATE 15-JUN-2012]
Here’s a workaround.
ini_set(‘mbstring.substitute_character’, «none»);
$text= mb_convert_encoding($text, ‘UTF-8’, ‘UTF-8’);
That will strip invalid characters from UTF-8 strings (so that you can insert it into a database, etc.). Instead of «none» you can also use the value 32 if you want it to insert spaces in place of the invalid characters.
Interestingly, setting different target locales results in different, yet appropriate, transliterations. For example:
//some German
$utf8_sentence = ‘Weiß, Goldmann, Göbel, Weiss, Göthe, Goethe und Götz’ ;
to test different combinations of convertions between charsets (when we don’t know the source charset and what is the convenient destination charset) this is an example :
Like many other people, I have encountered massive problems when using iconv() to convert between encodings (from UTF-8 to ISO-8859-15 in my case), especially on large strings.
The main problem here is that when your string contains illegal UTF-8 characters, there is no really straight forward way to handle those. iconv() simply (and silently!) terminates the string when encountering the problematic characters (also if using //IGNORE), returning a clipped string. The
?>
workaround suggested here and elsewhere will also break when encountering illegal characters, at least dropping a useful note («htmlentities(): Invalid multibyte sequence in argument in. «)
I have found a lot of hints, suggestions and alternative methods (it’s scary and in my opinion no good sign how many ways PHP natively provides to convert the encoding of strings), but none of them really worked, except for this one:
If you are getting question-marks in your iconv output when transliterating, be sure to ‘setlocale’ to something your system supports.
Some PHP CMS’s will default setlocale to ‘C’, this can be a problem.
use the «locale» command to find out a list..
For those who have troubles in displaying UCS-2 data on browser, here’s a simple function that convert ucs2 to html unicode entities :
Here is how to convert UCS-2 numbers to UTF-8 numbers in hex:
echo strtoupper ( ucs2toutf8 ( «06450631062D0020» ));
?>
Input:
06450631062D
Output:
D985D8B1D8AD
If you want to convert to a Unicode encoding without the byte order mark (BOM), add the endianness to the encoding, e.g. instead of «UTF-16» which will add a BOM to the start of the string, use «UTF-16BE» which will convert the string without adding a BOM.
I just found out today that the Windows and *NIX versions of PHP use different iconv libraries and are not very consistent with each other.
Here is a repost of my earlier code that now works on more systems. It converts as much as possible and replaces the rest with question marks:
I use this function that does’nt need any extension :
I have not tested it extensively, hope it may help.
I have used iconv to convert from cp1251 into UTF-8. I spent a day to investigate why a string with Russian capital ‘Р’ (sounds similar to ‘r’) at the end cannot be inserted into a database.
The problem is not in iconv. But ‘Р’ in cp1251 is chr(208) and ‘Р’ in UTF-8 is chr(208).chr(106). chr(106) is one of the space symbol which match ‘\s’ in regex. So, it can be taken by a greedy ‘+’ or ‘*’ operator. In that case, you loose ‘Р’ in your string.
For example, ‘ГР ‘ (Russian, UTF-8). Function preg_match. Regex is ‘(.+?)[\s]*’. Then ‘(.+?)’ matches ‘Г’.chr(208) and ‘[\s]*’ matches chr(106).’ ‘.
Although, it is not a bug of iconv, but it looks like it very much. That’s why I put this comment here.
Here is an example how to convert windows-1251 (windows) or cp1251(Linux/Unix) encoded string to UTF-8 encoding.