Таинственный код нашего генома
Расшифровка генетического код стала важным научным событием двадцатого века. Сейчас перед учеными появляются новые загадки о функционировании нашего генома.
Автор
Редакторы
Последовательность ДНК определяет строение белка с помощью триплетного генетического кода, в котором каждой аминокислоте соответствует три нуклеотида. Случайные мутации приводят к изменению последовательности нуклеотидов, в результате чего появляются новые варианты белков. Именно так до недавнего времени представляли себе ученые эволюцию белков. Но благодаря исследованиям последних лет оказалось, что помимо генетического кода есть и другие «коды», которые диктуют эволюции белков свои правила.
Одним из важных свойств генетического кода является его избыточность — каждая аминокислота, как правило, кодируется не одним, а 2–6 кодонами. Интересно, что при этом частота использования разных кодонов, отвечающих за одну и ту же аминокислоту, различается как в прокариотических, так и в эукариотических геномах [1]. У организмов с коротким жизненным циклом предпочтения одних кодонов другим связывают с необходимостью в увеличении эффективности транскрипции и стабильности мРНК [2], [3]. Однако в случае геномов млекопитающих такое объяснение подходит лишь для небольшого количества случаев, поэтому в последние годы ученые активно занимаются изучением особенностей геномов млекопитающих и причин предпочтительного использования тех или иных кодонов.
Важное значение в частоте использования кодонов играют транскрипционные факторы — к такому выводу пришла группа ученых из Университета Вашингтона под руководством Джона Стаматояннопоулоса (John A. Stamatoyannopoulos). В опубликованной в журнале Science статье обсуждается, как транскрипционные факторы могут управлять эволюцией белков посредством влияния на частоту использования кодонов [4].
Транскрипционные факторы (ТФ) — это белки, регулирующие транскрипцию генов при связывании с ДНК. ТФ могут повышать транскрипцию или снижать ее, влияя, таким образом, на количество мРНК и белка, соответствующих определенному гену. Долгое время считалось, что ТФ связываются только в некодирующей (не содержащей генов) части ДНК. В своем новом исследовании группа Стаматояннопоулоса выяснила, что на самом деле во многих генах человека ТФ связываются с кодирующими последовательностями ДНК (т.е. с теми, которые являются частью генов). Так как эффективность связывания ТФ с ДНК зависит от того, какие именно нуклеотиды находятся в сайте связывания, ТФ могут снижать возможное разнообразие кодонов в местах своей посадки (рис. 1). При этом даже нейтральные с точки зрения белка мутации (те, при которых последовательность аминокислот не меняется благодаря избыточности генетического кода) могут изменять эффективность связывания ТФ с ДНК и становиться материалом для естественного отбора. Получается, что эволюция белков определяется не только хорошо изученным генетическим кодом, но и другим особенным кодом — «кодом связывания ТФ». Ранее были описаны и некоторые другие «регуляторные» коды, которые контролируют организацию хроматина [5], пространственную структуру и сплайсинг мРНК [5], [6], эффективность трансляции [7], ко-трансляционный фолдинг белков [8] (рис. 2). Все они могут влиять на предпочтительное использование тех или иных кодонов.
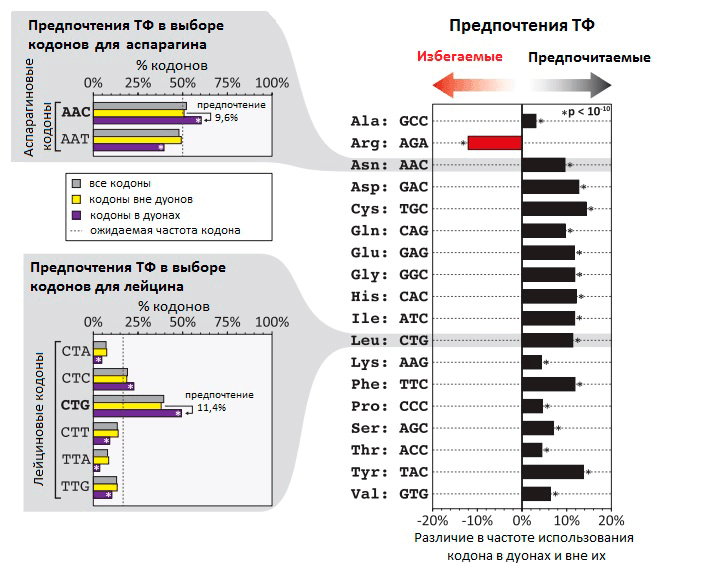
Рисунок 1. Неслучайная частота использования кодов в дуонах в местах связывания ТФ с ДНК. На гистограмме видно, что частота использования некоторых кодонов на 5–15% выше в дуонах, чем вне дуонов. В случае аргинина кодон AGA, напротив, гораздо реже встречается в дуонах, чем в других участках генома. В левой части рисунка — распределение частоты использования разных кодонов на примере кодонов для аспарагина и лейцина.
Насколько в геноме распространено применение дополнительных «регуляторных» кодов, которые перекрывают генетический код, и какое влияние они оказывают на эволюцию белков? Сотрудники лаборатории Стаматояннопоулоса попытались ответить на этот вопрос при исследовании «кода связывания ТФ». Чтобы выявить участки ДНК, связывающиеся с ТФ, они применили метод картирования с помощью дезоксирибонуклеазы I. Этот фермент разрушает одноцепочечные участки ДНК — если только они в этот момент не связаны с ТФ (в таком случае они сохранятся). Ученые исследовали 81 тип человеческих клеток, определив точные нуклеотидные последовательности связанных с ТФ участков генов. Оказалось, что приблизительно 14% кодонов в 86,9% генов человека связаны с различными транскрипционными факторами. В своей статье исследователи предлагают называть эти участки генов «дуонами», т.к. они кодируют два типа информации — информацию о белковой последовательности в виде генетического кода и информацию об экспрессии гена с помощью связывания ТФ. Для нормальной экспрессии гена необходимо связывание ДНК с ТФ, поэтому существуют определенные ограничения на использование различных кодонов, обусловленные строением ДНК-связывающего участка ТФ.
В геноме человека широко распространены однонуклеотидные полиморфизмы (single nucleotide polymorphisms, SNP) — различия последовательности гомологичных генов разных людей на один нуклеотид. Могут ли такие однонуклеотидные различия повлиять на эффективность связывания ТФ с ДНК? Чтобы узнать это, ученые из лаборатории Стаматояннопоулоса нашли на полученной ими карте дуонов почти 600 тыс. известных сайтов SNP, связанных с развитием какого-либо заболевания или проявлением определенного фенотипического признака. Оказалось, что 17,4% сайтов полиморфизма изменяют результаты картирования с помощью дезоксирибонуклеазы I, т.е. они, вероятно, снижают эффективность связывания ТФ с ДНК. Это изменение не зависит от того, является ли данный полиморфизм синонимичным или несинонимичным (т.е. влияет ли замена нуклеотида на замену аминокислоты в белке). Интересно, что значительная часть несинонимичных замен, хотя и приводит к изменению последовательности белка, не приводит к нарушению его функций. В этих случаях изменения нуклеотидной последовательности приводят только к нарушению связывания ТФ с ДНК. Эта находка поддерживает гипотезу о том, что SNP в кодирующей ДНК могут приводить к развитию заболеваний без влияния на функцию белка [9], [10]. Поэтому при изучении роли SNP в различных заболеваниях и при исследовании экзома необходимо учитывать весь спектр «регуляторных кодов», взаимодействующих с последовательностью гена.
«Регуляторные коды» далеко не всегда мирно и гармонично сосуществуют. В генах плодовой мушки Drosophila melanogaster ближе к концу экзонов наблюдается резкое снижение частоты использования оптимальных для трансляции кодонов и повышение частоты использования кодонов, которые облегчают сплайсинг мРНК [11]. Это показывает, что в ходе эволюции потребность в точном сплайсинге была выше, чем потребность в более эффективной трансляции. Также при исследовании дуонов и других ТФ-связывающих участков ДНК оказалось, что среди этих последовательностей нет стоп-кодонов.
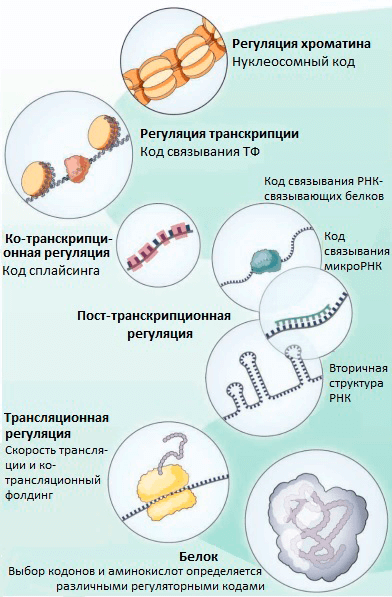
Рисунок 2. «Тайные коды» нашего генома, которые определяют частоту использования кодонов и выбор аминокислот в эволюции белков, независимо от выполнения белком его функций
Что же может обеспечить взаимовыгодное соседство «регуляторных» и генетического кодов? Одним из ключевых ограничений для белок-кодирующих генов является то, что последовательность гена должна обеспечивать нормальный фолдинг кодируемого белка. Мутации, нарушающие правильную укладку, с большой вероятностью будут отсеяны как вредные. Можно предположить, что когда необходимость правильного фолдинга отсутствует (например, в неструктурированных белках [12]), белок-кодирующая последовательность может содержать большее количество регуляторных элементов для различных «регуляторных кодов». Действительно ли это так, помогут узнать дальнейшие исследования.
Несмотря на то, что в работе Стаматояннопоулоса и его коллег было сделано много интересных наблюдений о функционировании «кода связывания ТФ», некоторые вопросы остаются открытыми. Например, авторы статьи отмечают, что ТФ гораздо реже связываются с генами с высокой экспрессией, но не ясно, как ТФ при связывании с белок-кодирующими участками ДНК могут воздействовать на транскрипцию этих генов. Возможно, что связывание ТФ в данном случае вызывает активацию альтернативного промотора или соседнего гена, снижая таким образом экспрессию гена с ТФ-связывающей последовательностью. С другой стороны, этот эффект может быть связан с перестройкой хроматина, которая приводит к снижению экспрессии ряда генов.
Новые исследования помогут ученым лучше понять, как различные «регуляторные коды» взаимодействуют друг с другом и с генетическим кодом. Интересно узнать, всегда ли природа могла найти оптимальное решение при сочетании разных кодов, или иногда возникали противоречия, приводящие к неоптимальным или вредным последствиям. Например, может оказаться, что белок-кодирующие последовательности ДНК, которым «трудно справиться» с обилием и разнообразием регуляторных элементов, активно используются патогенами при инфицировании хозяина. Обнаружение перекрывающихся «регуляторных кодов» в нашем геноме открывает новые перспективы для интерпретации различий и особенностей в последовательностях ДНК и указывает на то, что исследование генетического кода еще не подошло к концу.
Перевод редакционной колонки журнала Science [13].
Биология. 11 класс
§ 23. Генетический код и его свойства
Как вы знаете, признаки и свойства каждого организма определяются прежде всего белками, которые синтезируются в его клетках. Белки выполняют самые разнообразные функции (вспомните какие), обеспечивая тем самым протекание процессов жизнедеятельности. Можно сказать, что именно от этих биополимеров в первую очередь и зависит существование организма. Однако время функционирования белков, как и многих других биомолекул, весьма ограничено. Поэтому синтез белков в организме должен осуществляться непрерывно. Этот процесс протекает во всех клетках одноклеточных и многоклеточных организмов.
Вам также известно, что хранителем наследственной (генетической) информации, т. е. информации о первичной структуре белков, является ДНК. Участок молекулы ДНК, содержащий информацию о первичной структуре одного белка, получил название ген. Кроме того, генами называют участки ДНК, хранящие информацию о строении молекул рРНК и тРНК.
В биосинтезе белков, который осуществляется в рибосомах, ДНК прямого участия не принимает. Передача генетической информации, содержащейся в ДНК, к месту синтеза белка происходит с помощью посредника. Этим посредником является матричная (информационная) РНК (мРНК, иРНК), которая синтезируется на одной из цепей молекулы ДНК по принципу комплементарности.
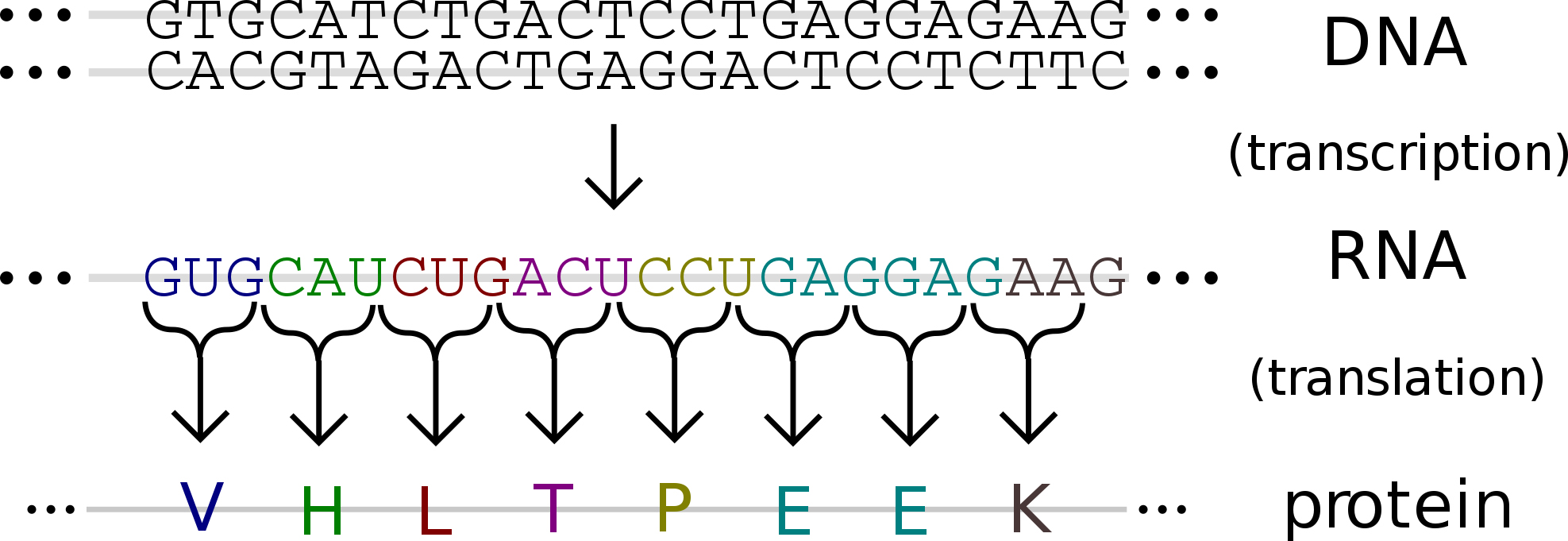
В молекулах ДНК и мРНК информация о первичной структуре белков «записана» в виде последовательности нуклеотидов. Сами же белки синтезируются из аминокислот. Значит, в природе существует особая система кодирования, на основании которой последовательность нуклеотидов расшифровывается в виде последовательности аминокислот молекул белков. Этот «шифр» называется генетическим кодом. Таким образом, генетический код — это система записи информации о первичной структуре белков в виде последовательности нуклеотидов ДНК (мРНК).
Генетический код обладает следующими свойствами.
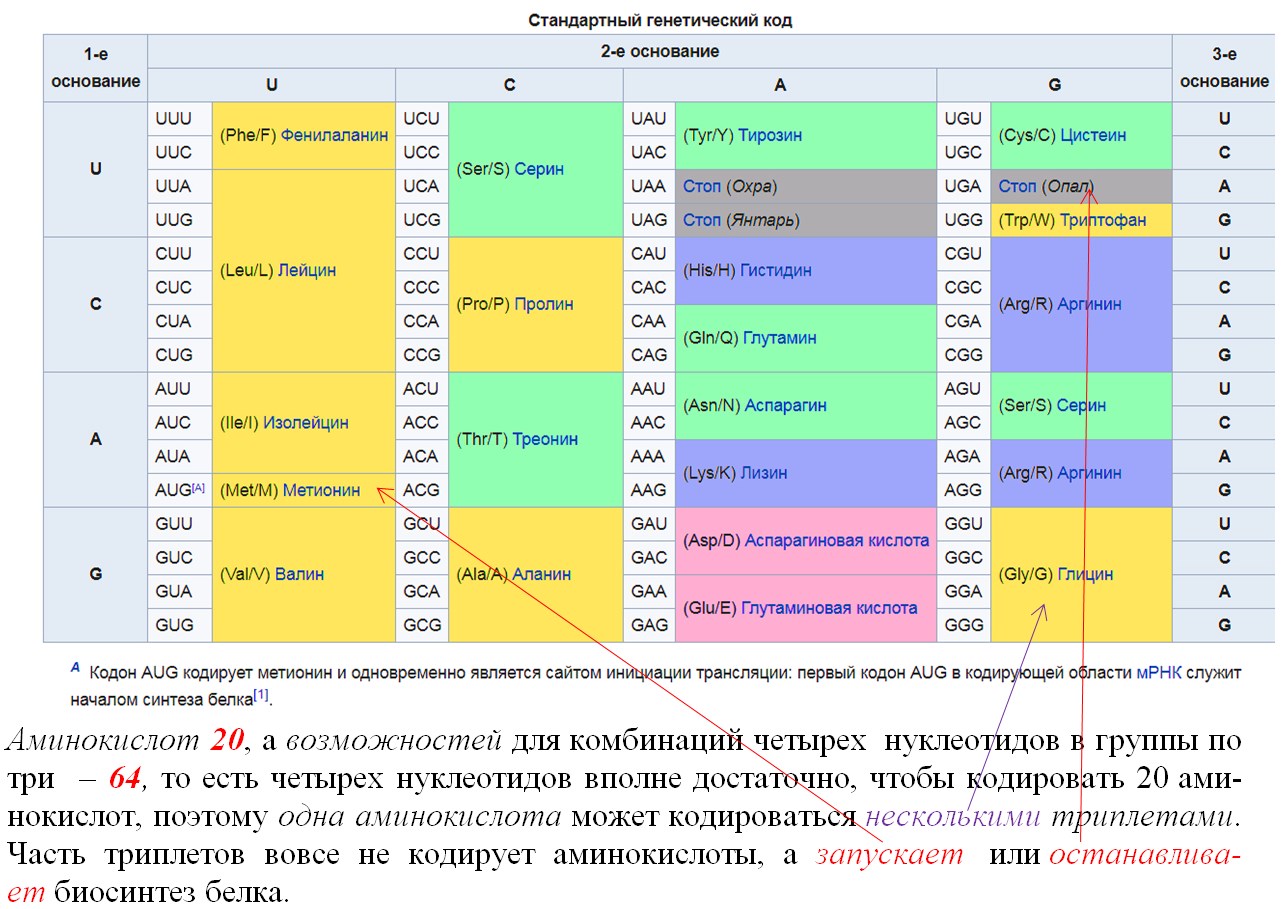
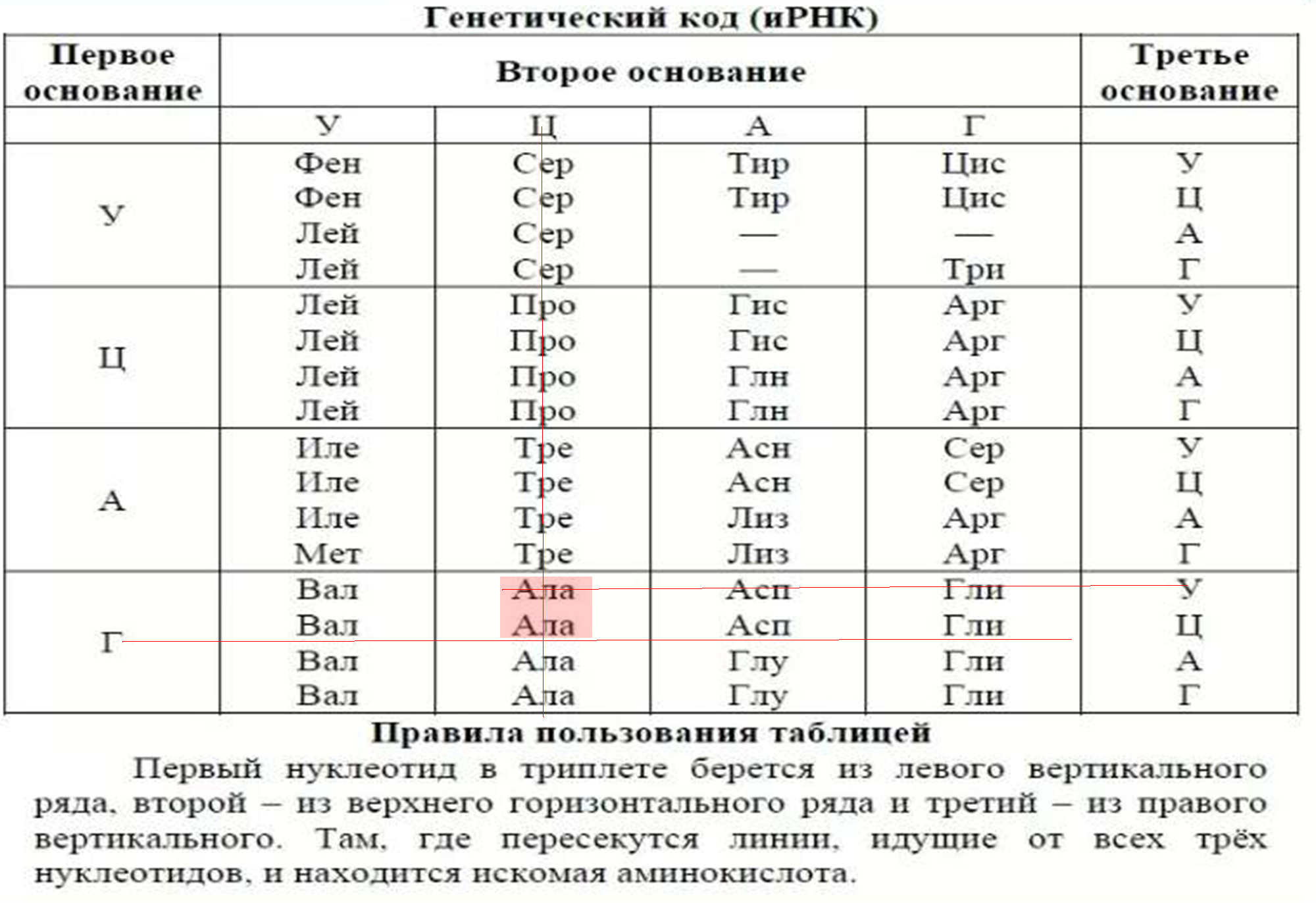
1. Код является триплетным. Это значит, что каждая аминокислота кодируется триплетом (кодоном) — сочетанием трех последовательно расположенных нуклеотидов. В состав молекул ДНК и РНК входит по 4 типа нуклеотидов. Если бы за определенную аминокислоту «отвечал» один нуклеотид, можно было бы закодировать только 4 из 20 белокобразующих аминокислот. Дублетов (по два нуклеотида) хватило бы лишь на 4 2 = 16 аминокислот. Количество возможных триплетов (сочетаний трех нуклеотидов) составляет 4 3 = 64. Этого с избытком хватает для кодирования всех 20 видов аминокислот (табл. 23.1).
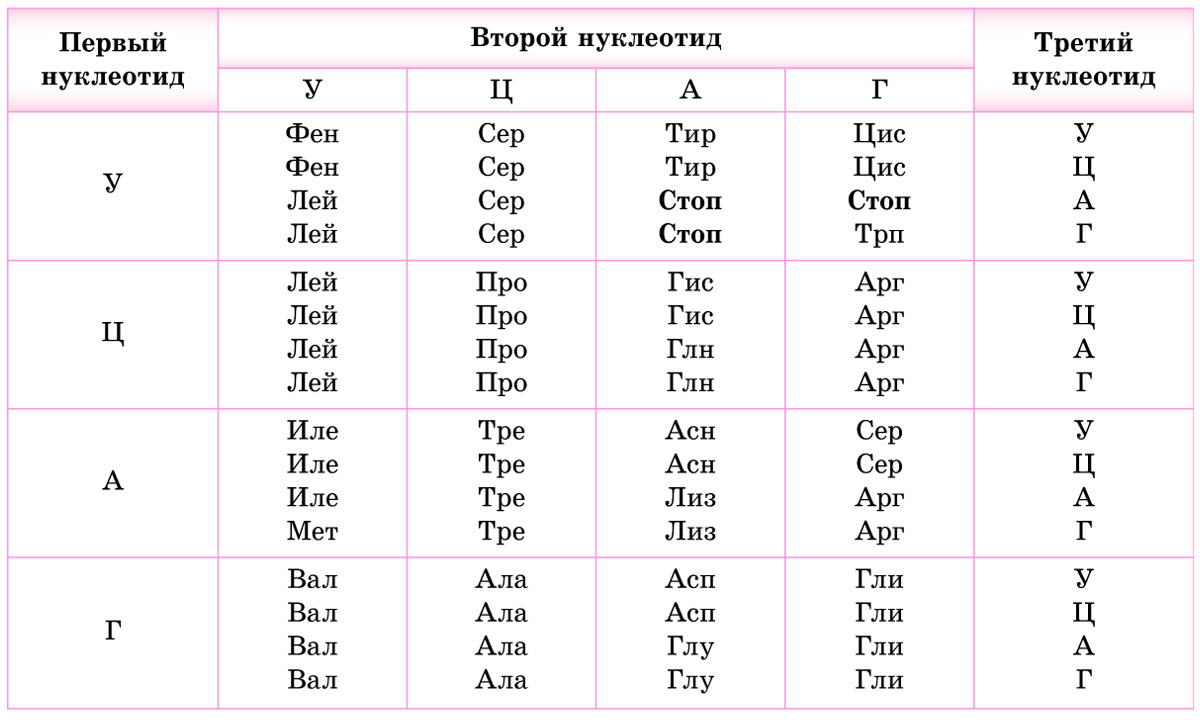
Обратите внимание, что 3 из 64 кодонов (в молекулах мРНК — УАА, УАГ и УГА) не кодируют аминокислоты. Это так называемые стоп-кодоны *или нонсенс-кодоны (от англ. nonsense — бессмыслица)*, они служат сигналом окончания синтеза белка. *Остальные триплеты называются смысловыми.*
* Генетический код расшифровали американские биохимики Р. Холли, Х. Г. Корана и М. Ниренберг в середине прошлого века. Работа стартовала в 1961 г. В бесклеточные системы, содержащие все необходимые компоненты для синтеза белка (рибосомы, аминокислоты, тРНК и др.), ученые сначала вводили искусственно синтезированные мРНК, состоящие только из одного типа нуклеотидов. Было выяснено, что в присутствии, например, полицитидиловой мРНК (ЦЦЦЦЦЦ. ) синтезируется полипептид, состоящий только из остатков аминокислоты пролина, в присутствии полиуридиловой (УУУУУУ. ) — из фенилаланина. Стало понятно, что кодону ЦЦЦ соответствует пролин, а триплет УУУ кодирует фенилаланин. К 1965 г., благодаря использованию искусственно синтезированных молекул мРНК с известными повторяющимися последовательностями нуклеотидов, удалось расшифровать все остальные триплеты. В 1968 г. это открытие было удостоено Нобелевской премии.*
2. Код однозначен — каждый триплет кодирует только одну аминокислоту.
3. Как уже отмечалось, число триплетов превышает количество кодируемых аминокислот. Поэтому генетический код является избыточным (вырожденным) — одна и та же аминокислота может кодироваться разными триплетами. Например, в мРНК цистеин (Цис) может быть закодирован триплетом УГУ или УГЦ, треонин (Тре) — АЦУ, АЦЦ, АЦА или АЦГ. Некоторые аминокислоты, например лейцин (Лей), кодируются шестью различными триплетами, в то же время метионину (Мет) и триптофану (Трп) соответствует только по одному кодону (проверьте по таблице генетического кода).
4. Код не перекрывается — один и тот же нуклеотид не может одновременно входить в состав двух соседних триплетов.
5. Код непрерывен. В полинуклеотидной цепи нуклеотиды располагаются непрерывно и соседние триплеты ничем не отделены друг от друга. Это значит, что фактически деление на триплеты условно — все зависит от того, с какого именно нуклеотида начинается их считывание. Поэтому в клетках считывание информации, содержащейся в генах, всегда начинается со строго определенного нуклеотида.
Если в составе гена происходит изменение количества нуклеотидов (их выпадение или вставка) на число, не кратное трем, наблюдается так называемый сдвиг рамки считывания (рис. 23.1). Это прив одит к существенному изменению последовательности аминокислот в белке, который кодируется измененным геном. В некоторых случаях сдвиг рамки считывания приводит к возникновению стоп-кодонов, из-за чего синтез белка обрывается.
*Суть происходящего при сдвиге рамки считывания можно понять на следующем примере. Прочитайте предложение, составленное из трехбуквенных слов (аналогично триплетам):
ЖИЛ БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ.
В этом предложении заключен определенный смысл, понять который можно и без знаков препинания. Выпадение одной буквы аналогично выпадению одного нуклеотида. Оно приводит к изменению порядка считывания и потере смысла:
ЖЛБ ЫЛК ОТТ ИХБ ЫЛС ЕРМ ИЛМ НЕТ ОТК ОТ — выпадение второй буквы.
То же самое произошло бы и после вставки лишней буквы. В случае замены одной буквы либо при изменении их количества на три смысл предложения меняется не столь значительно. Например:
ЖИВ БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — замена третьей буквы;
БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — выпадение первых трех букв.
Однако смысл предложения (в нашей аналогии — первичная структура белка) во многом зависит от положения измененных букв (нуклеотидов). Так, смысл может существенно исказиться:
ЖИЛ БОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — выпадение пятой, шестой и седьмой букв.
Аналогичная ситуация наблюдается и с белками. В зависимости от расположения замененной (утраченной, добавленной) аминокислоты молекула белка может сохранить пространственную конфигурацию и функции, частично изменить их или же полностью утратить свои исходные характеристики.*
Как уже отмечалось, правильное считывание генетической информации обеспечивается только тогда, когда оно начинается со строго определенной позиции. У эукариот стартовым кодоном молекулы мРНК является триплет АУГ. Именно с него и начинается считывание.
6. Код универсален — у всех живых организмов одним и тем же триплетам соответствуют одни и те же аминокислоты. Иными словами, у всех организмов генетический код расшифровывается одинаково (за редким исключением). Это свидетельствует о единстве происхождения живых организмов.
*Некоторые вариации генетического кода обнаружены у бактерий, инфузорий, дрожжей, в коде митохондриальной ДНК и т. д. Например, у бактерий триплет мРНК ГУГ может играть роль стартового кодона, а у эукариот он предназначен только для кодирования аминокислоты валин. В митохондриях млекопитающих триплет УГА кодирует триптофан, в то время как в матричной РНК, синтезированной в ядре клетки, он служит стоп-кодоном. И наоборот, в коде митохондрий триплеты АГА и АГГ являются сигналами окончания синтеза белка, а в «основной версии» генетического кода им соответствует аминокислота аргинин.*
Биосинтез белка и нуклеиновых кислот. Гены, генетический код
В обмене веществ организма ведущая роль принадлежит белкам и нуклеиновым кислотам.
Белковые вещества составляют основу всех жизненно важных структур клетки, обладают необычайно высокой реакционной способностью, наделены каталитическими функциями.
Нуклеиновые кислоты входят в состав важнейшего органа клетки — ядра, а также цитоплазмы, рибосом, митохондрий и т. д. Нуклеиновые кислоты играют важную, первостепенную роль в наследственности, изменчивости организма, в синтезе белка.
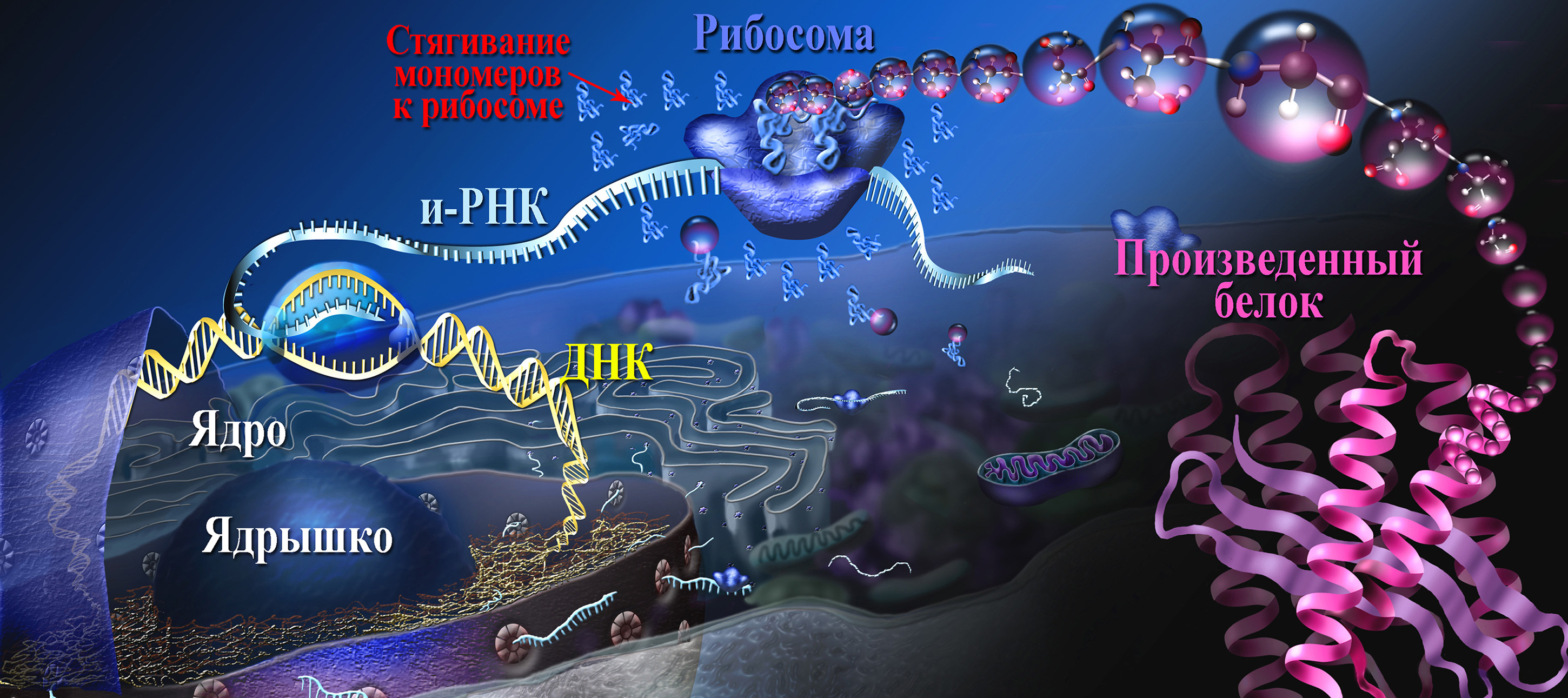
План синтеза белка хранится в ядре клетки, а непосредственно синтез происходит вне ядра, поэтому необходима служба доставки закодированного плана из ядра к месту синтеза. Такую службу доставки исполняют молекулы РНК.
После дальнейших изменений этот вид закодированной и-РНК готов. и-РНК выходит из ядра и направляется к месту синтеза белка, где буквы и-РНК расшифровываются. Каждый набор из трех букв и-РНК образует «букву», обозначающее одну конкретную аминокислоту.
Другой вид РНК отыскивает эту аминокислоту, захватывает ее с помощью фермента и доставляет к месту синтеза белка. Эта РНК называется транспортной, или т-РНК. По мере прочтения и перевода сообщения и-РНК цепочка аминокислот растет. Эта цепочка закручивается и укладывается в уникальную форму, создавая один вид белка. Примечателен даже процесс укладки белка: на то, чтобы с помощью компьютера просчитать все варианты укладки белка среднего размера, состоящего из 100 аминокислот, потребовалось бы 1027 (!) лет. А для образования в организме цепочки из 20 аминокислот требуется не более одной секунды, и этот процесс происходит непрерывно во всех клетках тела.
Гены, генетический код и его свойства.
На Земле живет около 7 млрд людей. Если не считать 25—30 млн пар однояйцовых близнецов, то генетически все люди разные : каждый уникален, обладает неповторимыми наследственными особенностями, свойствами характера, способностями, темпераментом.
Такие различия объясняются различиями в генотипах—наборах генов организма; у каждого он уникален. Генетические признаки конкретного организма воплощаются в белках — следовательно, и строение белка одного человека отличается, хотя и совсем немного, от белка другого человека.
Ген – единица наследственной информации организма, которой соответствует отдельный участок ДНК
Генетический код состоит из троек (триплетов) нуклеотидов ДНК, комбинирующихся в разной последовательности (ААТ, ГЦА, АЦГ, ТГЦ и т.д.), каждый из которых кодирует определенную аминокислоту (которая будет встроена в полипептидную цепь).
Основные свойства генетического кода:

2. Избыточность ( вырожденность ) кода является следствием его триплетности и означает то, что одна аминокислота может кодироваться несколькими триплетами (поскольку аминокислот 20, а триплетов — 64), за исключением метионина и триптофана, которые кодируются только одним триплетом. Кроме того, некоторые триплеты выполняют специфические функции: в молекуле и-РНК триплеты УАА, УАГ, УГА — являются терминирующими кодонами, т. е. стоп-сигналами, прекращающими синтез полипептидной цепи. Триплет, соответствующий метионину (АУГ), стоящий в начале цепи ДНК, не кодирует аминокислоту, а выполняет функцию инициирования (возбуждения) считывания.
4. Коллинеарность кода, т.е. последовательность нуклеотидов в гене точно соответствует последовательности аминокислот в белке.
Существуют таблицы генетического кода для расшифровки кодонов и- РНК и построения цепочек белковых молекул.
Реакции матричного синтеза.
В живых системах встречается реакции, неизвестные в неживой природе — реакции матричного синтеза.
Термином «матрица» в технике обозначают форму, употребляемую для отливки монет, медалей, типографского шрифта: затвердевший металл в точности воспроизводит все детали формы, служившей для отливки. Матричный синтез напоминает отливку на матрице: новые молекулы синтезируются в точном соответствии с планом, заложенным в структуре уже существующих молекул.
Матричный принцип лежит в основе важнейших синтетических реакций клетки, та-ких, как синтез нуклеиновых кислот и белков. В этих реакциях обеспечивается точная, строго специфичная последовательность мономерных звеньев в синтезируемых полимерах.
Мономерные молекулы, из которых синтезируется полимер, — нуклеотиды или аминокислоты — в соответствии с принципом комплементарности располагаются и фиксируются на матрице в строго определенном, заданном порядке.
Затем происходит «сшивание» мономерных звеньев в полимерную цепь, и готовый полимер сбрасывается с матрицы.
После этого матрица готова к сборке новой полимерной молекулы. Понятно, что как на данной форме может производиться отливка только какой-то одной монеты, одной буквы, так и на данной матричной молекуле может идти «сборка» только какого-то одного полимера.
Матричный тип реакций — специфическая особенность химизма живых систем. Они являются основой фундаментального свойства всего живого — его способности к воспроизведению себе подобного.
Реакции матричного синтеза
Молекула ДНК состоит из двух комплементарных цепей. Эти цепи удерживаются слабыми водородными связями, способными разрываться под действием ферментов. Молекула ДНК способна к самоудвоению (репликации), причем на каждой старой половине молекулы синтезируется новая ее половина.
Кроме того, на молекуле ДНК может синтезироваться молекула и-РНК, которая затем переносит полученную от ДНК информацию к месту синтеза белка.
Передача информации и синтез белка идут по матричному принципу, сравнимому с работой печатного станка в типографии. Информация от ДНК многократно копируется. Если при копировании произойдут ошибки, то они повторятся во всех последующих копиях.
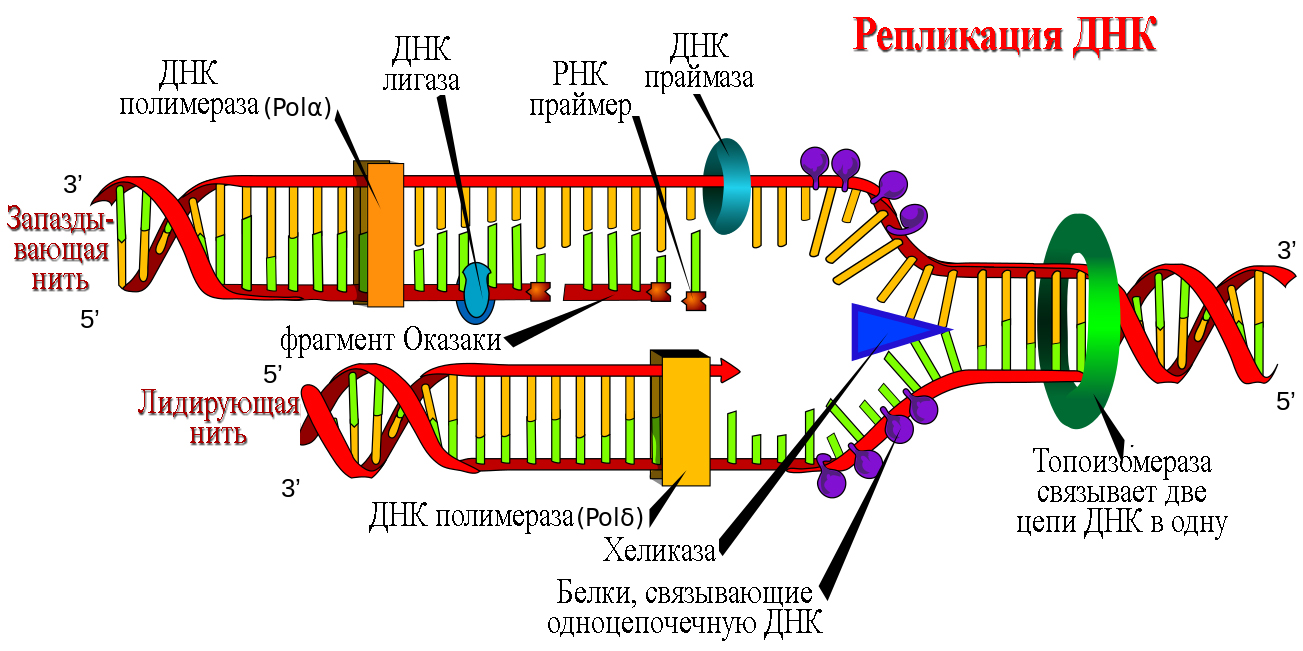
Правда, некоторые ошибки при копировании информации молекулой ДНК могут исправляться — процесс устранения ошибок называется репарацией. Первой из реакций в процессе передачи информации является репликация молекулы ДНК и синтез новых цепей ДНК.
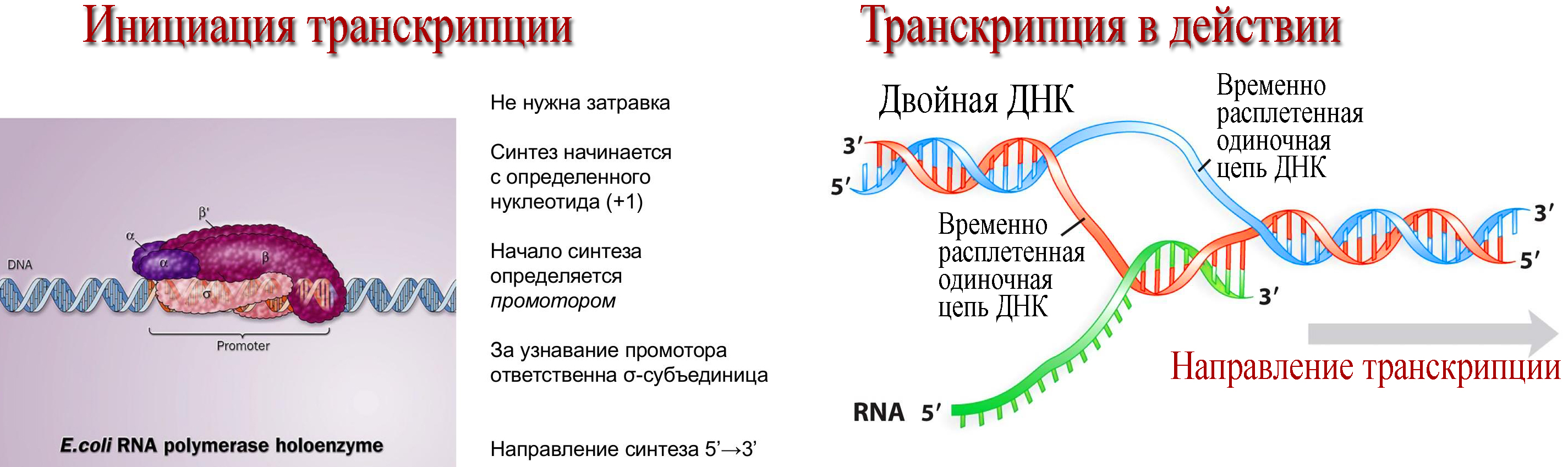
2. Транскрипция (от лат. transcriptio — переписывание) — процесс синтеза РНК с использованием ДНК в качестве матрицы, происходящий во всех живых клетках. Другими словами, это перенос генетической информации с ДНК на РНК.
Готовая молекула и-РНК выходит в цитоплазму на рибосомы, где происходит синтез полипептидных цепей.
3. Трансляция (от лат. translatio — перенос, перемещение) — процесс синтеза белка из аминокислот на матрице информационной (матричной) РНК (иРНК, мРНК), осуществляемый рибосомой. Иными словами, это процесс перевода информации, со-держащейся в последовательности нуклеотидов и-РНК, в последовательность амино-кислот в полипептиде.
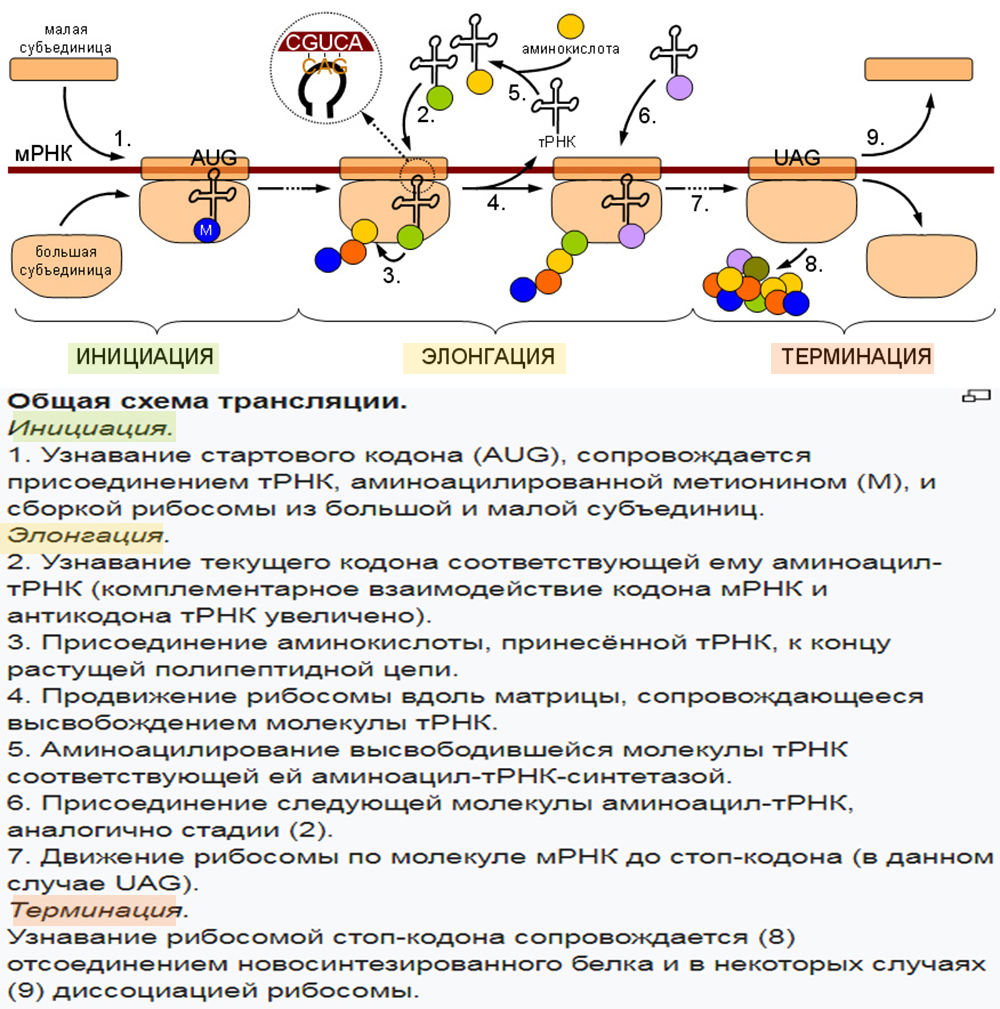
4. Обратная транскрипция — это процесс образования двуцепочечной ДНК на основании информации из одноцепочечной РНК. Данный процесс называется обратной транскрипцией, так как передача генетической информации при этом происходит в «обратном», относительно транскрипции, направлении. Идея обратной транскрипции вначале была очень непопулярна, так как противоречила центральной догме молекулярной биологии, которая предполагала, что ДНК транскрибируется в РНК и далее транслируется в белки.
Последовательность матричных реакций при биосинтезе белков можно представить в виде схемы.
Таким образом, биосинтез белка – это один из видов пластического обмена, в ходе которого наследственная информация, закодированная в генах ДНК, реализуется в определенную последовательность аминокислот в белковых молекулах.
В результате активирования аминокислота становится более лабильной и под действием того же фермента связывается с т-РНК. Каждой аминокислоте соответствует строго специфическая т-РНК, которая находит «свою» аминокислоту и переносит ее в рибосому.
Следовательно, в рибосому поступают различные активированные аминокислоты, соединенные со своими т-РНК. Рибосома представляет собой как бы конвейер для сборки цепочки белка из поступающих в него различных аминокислот.
Одновременно с т-РНК, на которой «сидит» своя аминокислота, в рибосому поступает «сигнал» от ДНК, которая содержится в ядре. В соответствии с этим сигналом в рибосоме синтезируется тот или иной белок.
Направляющее влияние ДНК на синтез белка осуществляется не непосредственно, а с помощью особого посредника – матричной или информационной РНК (м-РНК или и-РНК), которая синтезируется в ядре под влиянием ДНК, поэтому ее состав отражает состав ДНК. Молекула РНК представляет собой как бы слепок с формы ДНК. Синтезированная и-РНК поступает в рибосому и как бы передает этой структуре план — в каком порядке должны соединяться друг с другом поступившие в рибосому активированные аминокислоты, чтобы синтезировался определенный белок. Иначе, генетическая информация, закодированная в ДНК, передается на и- РНК и далее на белок.
Молекула и-РНК поступает в рибосому и прошивает ее. Тот ее отрезок, который находится в данный момент в рибосоме, определенный кодоном (триплет), взаимо-действует совершенно специфично с подходящим к нему по строению триплетом (антикодоном) в транспортной РНК, которая принесла в рибосому аминокислоту.
Транспортная РНК со своей аминокислотой подходит к определенному кодону и-РНК и соединяется с ним; к следующему, соседнему участку и- РНК присоединяется другая т-РНК с другой аминокислотой и так до тех пор, пока не будет считана вся цепочка и-РНК, пока не нанижутся все аминокислоты в соответствующем порядке, образуя молекулу белка. А т-РНК, которая доставила аминокислоту к определенному участку полипептидной цепи, освобождается от своей аминокислоты и выходит из рибосомы.
Затем снова в цитоплазме к ней может присоединиться нужная аминокислота, и она снова перенесет ее в рибосому. В процессе синтеза белка участвует одновременно не одна, а несколько рибосом — полирибосомы.
Основные этапы передачи генетической информации:
Этапы универсальны для всех живых существ, но временные и пространственные взаимоотношения этих процессов различаются у про- и эукариотов.
У прокариот транскрипция и трансляция могут осуществляться одновременно, поскольку ДНК находится в цитоплазме. У эукариот транскрипция и трансляция строго разделены в пространстве и времени: синтез различных РНК происходит в ядре, после чего молекулы РНК должны покинуть пределы ядра, пройдя через ядерную мембрану. Затем в цитоплазме РНК транспортируются к месту синтеза белка.