Изучаем команды Linux: sed
Оригинал: Learning Linux Commands: sed
Автор: Rares Aioanei
Дата публикации: 19 ноября 2011 года
Перевод: А. Кривошей
Дата перевода: июль 2012 г.
Николай Игнатушко проверил на GNU sed version 4.2.1 в дистрибутиве Gentoo все команды, упомянутые в этой статье. Не все скрипты хорошо отрабатывали на версии GNU sed. Но дело касалось мелочей, которые исправлены. Только скрипт по замене hill на mountains пришлось существенно переделать.
1. Введение
Добро пожаловать во вторую часть нашей серии, которая посвящена sed, версии GNU. Существует несколько версий sed, которые доступны на разных платформах, но мы сфокусируемся на GNU sed версии 4.x. Многие из вас слышали о sed, или уже использовали его, скорее всего в качестве инструмента замены. Но это только одно из предназначений sed, и мы постараемся показать вам все аспекты использования этой утилиты. Его название расшифровывается как «Stream EDitor» и слово «stream» (поток) в данном случае может означать файл, канал, или просто stdin. Мы надеемся, что у вас уже есть базовые знания о Linux, а если вы уже работали с регулярными выражениями, или по крайней мере знаете, что это такое, то все для вас будет намного проще. Объем статьи не позволяет включить в нее полное руководство по регулярным выражениям, вместо этого мы озвучим базовые концепции и дадим большое количество примеров использования sed.
2. Установка
Здесь не нужно много рассказывать. Скорее все sed у вас уже установлен, так как он используется различными системными скриптами, а также пользователями Linux, которые хотят повысить эффективность своей работы. Вы можете узнать, какая версия sed у вас установлена, с помощью команды:
В моей системе эта команда показывает, что у меня установлен GNU sed 4.2.1 плюс дает ссылку на домашнюю страницу программы и другие полезные сведения. Пакет называется «sed» независимо от дистрибутива, кроме Gentoo, где он присутствует неявно.
3. Концепции
Перед тем, как идти дальше, мы считаем важным акцентировать внимание на том, что делает «sed», так как словосочетание «потоковый редактор» мало что говорит о его назначении. sed принимает на входе текст, выполняет заданные операции над каждой строкой (если не задано другое) и выводит модифицированный текст. Указанными операциями могут быть добавление, вставка, удаление или замена. Это не так просто, как выглядит: предупреждаю, что имеется большое количество опций и их комбинаций, которые могут сделать команду sed очень трудной для понимания. Поэтому мы рекомендуем вам изучить основы регулярных выражений, чтобы понимать, как это работает. Перед тем, как приступить к руководству, мы хотели бы поблагодарить Eric Pement и других за вдохновление и за то, что он сделал для всех, кто хочет изучать и использовать sed.
4. Регулярные выражения
Так как команды (скрипты) sed для многих остаются загадкой, мы чувствуем, что наши читатели должны понимать базовые концепции, а не слепо копировать и вставлять команды, значения которых они не понимают. Когда человек хочет понять, что представляют собой регулярные выражения, ключевым словом является «соответствие», или, точнее, «шаблон соответствия». Например, в отчете для своего департамента вы написали имя Nick, обращаясь к сетевому архитектору. Но Nick ушел, а на его место пришел John, поэтому теперь вы должны заменить слово Nick на John. Если файл с отчетом называется report.txt, вы должны выполнить следующую команду:
По умолчанию sed использует stdout, вы можете использовать оператор перенаправления вывода, как показано в примере выше. Это очень простой пример, но мы проиллюстрировали несколько моментов: мы ищем все соответствия шаблону «Nick» и заменяем во всех случаях на «John». Отметим, что sed призводит поиск с учетом регистра, поэтому будьте внимательны и проверьте выходной файл, чтобы убедиться, что все замены были выполнены. Приведенный выше пример можно было записать и так:
Команда sed Linux
В этой статье мы рассмотрим основы использования команды sed linux, её синтаксис, а также синтаксис регулярных выражений, который используется непосредственно для поиска и замены в файлах.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
А вот её основные опции:
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
Примеры использования sed
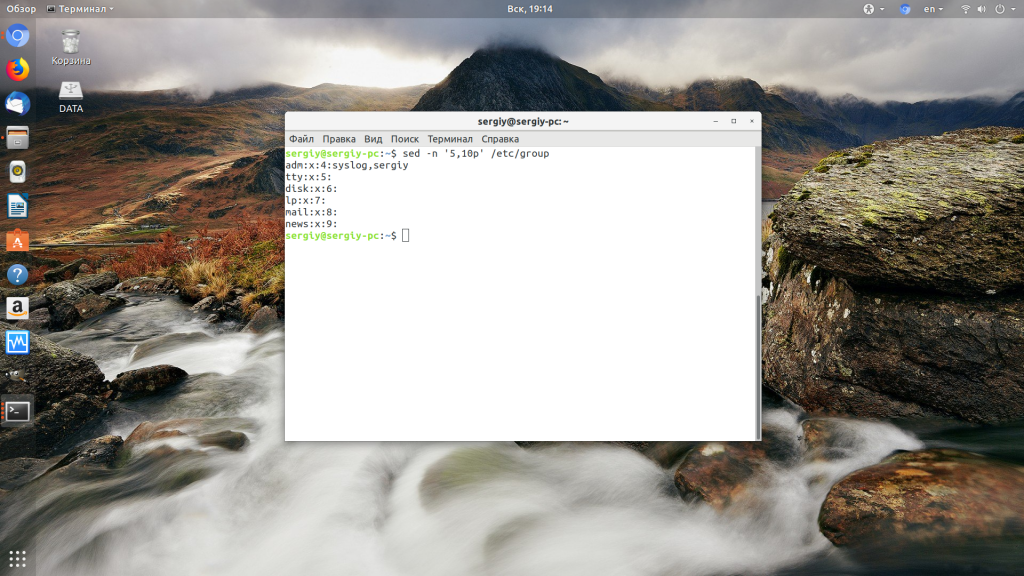
Или можно вывести весь файл, кроме строк с первой по двадцатую:

sed ‘s/root/losst/g’ /etc/group

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:
sed ‘1,10 s/0/1000/g’ /etc/group

Переходим ещё ближе к регулярным выражениям, удалим все пустые строки или строки с комментариями из конфига Apache:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:
sed ‘s/[$p*]/losst_p/g’ /etc/group

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf | sudo tee /etc/apache2/apache2.conf

Выводы
Из этой статьи вы узнали что представляет из себя команда sed Linux. Как видите, это очень гибкий инструмент, который позволяет делать с текстом очень многое. Он сложный в освоении, но с помощью него очень удобно решать многие задачи редактирования конфигурационных файлов или фильтрации вывода.
Bash-скрипты, часть 7: sed и обработка текстов
В прошлый раз мы говорили о функциях в bash-скриптах, в частности, о том, как вызывать их из командной строки. Наша сегодняшняя тема — весьма полезный инструмент для обработки строковых данных — утилита Linux, которая называется sed. Её часто используют для работы с текстами, имеющими вид лог-файлов, конфигурационных и других файлов.

Если вы, в bash-скриптах, каким-то образом обрабатываете данные, вам не помешает знакомство с инструментами sed и gawk. Тут мы сосредоточимся на sed и на работе с текстами, так как это — очень важный шаг в нашем путешествии по бескрайним просторам разработки bash-скриптов.
Сейчас мы разберём основы работы с sed, а так же рассмотрим более трёх десятков примеров использования этого инструмента.
Основы работы с sed
Утилиту sed называют потоковым текстовым редактором. В интерактивных текстовых редакторах, наподобие nano, с текстами работают, используя клавиатуру, редактируя файлы, добавляя, удаляя или изменяя тексты. Sed позволяет редактировать потоки данных, основываясь на заданных разработчиком наборах правил. Вот как выглядит схема вызова этой команды:
Вот что получится при выполнении этой команды.
Простой пример вызова sed
Выше приведён примитивный пример использования sed, нужный для того, чтобы ввести вас в курс дела. На самом деле, sed можно применять в гораздо более сложных сценариях обработки текстов, например — для работы с файлами.
Ниже показан файл, в котором содержится фрагмент текста, и результаты его обработки такой командой:
Текстовый файл и результаты его обработки
Здесь применён тот же подход, который мы использовали выше, но теперь sed обрабатывает текст, хранящийся в файле. При этом, если файл достаточно велик, можно заметить, что sed обрабатывает данные порциями и выводит то, что обработано, на экран, не дожидаясь обработки всего файла.
Выполнение наборов команд при вызове sed
К каждой строке текста из файла применяются обе команды. Их нужно разделить точкой с запятой, при этом между окончанием команды и точкой с запятой не должно быть пробела.
Для ввода нескольких шаблонов обработки текста при вызове sed, можно, после ввода первой одиночной кавычки, нажать Enter, после чего вводить каждое правило с новой строки, не забыв о закрывающей кавычке:
Вот что получится после того, как команда, представленная в таком виде, будет выполнена.
Другой способ работы с sed
Чтение команд из файла
Вот содержимое файла mycommands :
Вызовем sed, передав редактору файл с командами и файл для обработки:
Результат при вызове такой команды аналогичен тому, который получался в предыдущих примерах.
Использование файла с командами при вызове sed
Флаги команды замены
Внимательно посмотрите на следующий пример.
Вот что содержится в файле, и что будет получено после его обработки sed.
Исходный файл и результаты его обработки
Команда замены нормально обрабатывает файл, состоящий из нескольких строк, но заменяются только первые вхождения искомого фрагмента текста в каждой строке. Для того, чтобы заменить все вхождения шаблона, нужно использовать соответствующий флаг.
Схема записи команды замены при использовании флагов выглядит так:
Выполнение этой команды можно модифицировать несколькими способами.
Вызов команды замены с указанием позиции заменяемого фрагмента
Тут мы указали, в качестве флага замены, число 2. Это привело к тому, что было заменено лишь второе вхождение искомого шаблона в каждой строке. Теперь опробуем флаг глобальной замены — g :
Как видно из результатов вывода, такая команда заменила все вхождения шаблона в тексте.
Как результат, при запуске sed в такой конфигурации на экран выводятся лишь строки (в нашем случае — одна строка), в которых найден заданный фрагмент текста.
Использование флага команды замены p
Сохранение результатов обработки текста в файл
Символы-разделители
Однако, выглядит всё это не очень-то хорошо. Всё дело в том, что так как прямые слэши используются в роли символов-разделителей, такие же символы в передаваемых sed строках приходится экранировать. В результате страдает читаемость команды.
К счастью, sed позволяет нам самостоятельно задавать символы-разделители для использования их в команде замены. Разделителем считается первый символ, который будет встречен после s :
В данном случае в качестве разделителя использован восклицательный знак, в результате код легче читать и он выглядит куда опрятнее, чем прежде.
Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:
Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:
Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Удаление строк
Вызов команды выглядит так:
Мы хотим, чтобы из текста была удалена третья строка. Обратите внимание на то, что речь не идёт о файле. Файл останется неизменным, удаление отразится лишь на выводе, который сформирует sed.
Удаление третьей строки
Если при вызове команды d не указать номер удаляемой строки, удалены будут все строки потока.
Вот как применить команду d к диапазону строк:
Удаление диапазона строк
А вот как удалить строки, начиная с заданной — и до конца файла:
Удаление строк до конца файла
Строки можно удалять и по шаблону:
Удаление строк по шаблону
При вызове d можно указывать пару шаблонов — будут удалены строки, в которых встретится шаблон, и те строки, которые находятся между ними:
Удаление диапазона строк с использованием шаблонов
Вставка текста в поток
С помощью sed можно вставлять данные в текстовый поток, используя команды i и a :
Теперь взглянем на команду a :
Как видно, эти команды добавляют текст до или после данных из потока. Что если надо добавить строку где-нибудь посередине?
Команда i с указанием номера опорной строки
Проделаем то же самое с командой a :
Команда a с указанием номера опорной строки
Замена строк
Команда c позволяет изменить содержимое целой строки текста в потоке данных. При её вызове нужно указать номер строки, вместо которой в поток надо добавить новые данные:
Замена строки целиком
Если воспользоваться при вызове команды шаблоном в виде обычного текста или регулярного выражения, заменены будут все соответствующие шаблону строки:
Замена строк по шаблону
Замена символов
Команда y работает с отдельными символами, заменяя их в соответствии с переданными ей при вызове данными:
Используя эту команду, нужно учесть, что она применяется ко всему текстовому потоку, ограничить её конкретными вхождениями символов нельзя.
Вывод номеров строк
Вывод номеров строк
Потоковый редактор вывел номера строк перед их содержимым.
Вывод номеров строк, соответствующих шаблону
Чтение данных для вставки из файла
Вставка в поток содержимого файла
Вот что произойдёт, если применить при вызове команды r шаблон:
Использование шаблона при вызове команды r
Содержимое файла будет вставлено после каждой строки, соответствующей шаблону.
Пример
Решить эту задачу можно, воспользовавшись командами r и d потокового редактора sed:
Замена указателя места заполнения на реальные данные
Итоги
Сегодня мы рассмотрели основы работы с потоковым редактором sed. На самом деле, sed — это огромнейшая тема. Его изучение вполне можно сравнить с изучением нового языка программирования, однако, поняв основы, вы сможете освоить sed на любом необходимом вам уровне. В результате ваши возможности по обработке с его помощью текстов будет ограничивать лишь воображение.
На сегодня это всё. В следующий раз поговорим о языке обработки данных awk.
Уважаемые читатели! А вы пользуетесь sed в повседневной работе? Если да — поделитесь пожалуйста опытом.
HuMan: sed
Введение
Программа sed способна выполнять сложные задания, и нужно потратить время, чтобы научиться эти задания формулировать.
Но наряду со сложными действиями, у команды sed есть простые, но весьма полезные возможности, освоить которые не труднее, чем прочие команды Юникс. Не позволяйте себе из-за сложности освоения всей программы, отказываться от ее простых аспектов.
Мы начнем от простого к сложному, так что вы всегда сможете понять, где следует остановиться.
Проще не бывает. А вот пример с вводом из файла zar.txt:
Я не брал выражение s/ОБРАЗЕЦ/ЗАМЕНУ/ в кавычки, так как данный пример не нуждается в кавычках, но если бы в нем присутствовали метасимволы, то кавычки были бы обязательны. Чтобы не ломать себе каждый раз голову, и не ошибиться ненароком, всегда ставьте кавычки, лучше более «сильные» одинарные, это хорошая привычка. Кашу маслом не испортишь. Я тоже во всех последующих примерах не буду манкировать кавычками.
Как мы видим, заменяющая команда s имеет четыре составляющих:
Это называется «частокол» и выглядит весьма уродливо, а главное, непонятно.
Уникальность программы sed в том, что она позволяет использовать любой разделитель, например знак подчеркивания:
Если в поисках разделителя, который вам нравится, вы получаете сообщение «незавершенная команда `s'», значит этот символ не годится в качестве разделителя, или вы просто забыли поставить один-два разделителя.
В этой статье я вынужден использовать традиционный разделитель (/) чтобы не сбивать читателя с толку, но в случае необходимости стану использовать в качестве разделителя тильду (
Регулярные выражения (РВ)
Тема регулярных выражений настолько обширна, что ей посвящены целые книги (смотри ссылки в конце статьи). Тем не менее, говорить всерьез о редакторе sed, не применяя регулярных выражений, также непродуктивно, как разговаривать о тригонометрии при помощи счетных палочек. Поэтому необходимо рассказать хотя бы о тех регулярных выражениях, которые часто используются с программой sed.
с Или любая другая буква. Большинство букв, цифр и прочих неспециальных символов считаются регулярными выражениями, представляющими сами себя.
* Астериск, следующий за каким-либо символом или регулярным выражением, означает любое число (в том числе и нулевое) повторов этого символа или регулярного выражения.
\+ Означает один или более повтор символа или регулярного выражения.
\? Означает ни одного или один повтор.
\ Означает ровно i повторов.
\ Число повторов находится в интервале от i до j включительно.
\ Число повторов больше или равно i.
\ Число повторов меньше или равно j.
\(RE\) Запомнить регулярное выражение или его часть с целью дальнейшего использования как единое целое. Например, \(а-я\)* будет искать любое сочетание любого количества (в том числе и нулевого) строчных букв.
. Означает любой символ, кроме символа новой строки.
^ Означает нулевое выражение в начале строки. Другими словами, то, перед чем стоит этот знак, должно появляться в начале строки. Например, ^#include будет искать строки, начинающиеся с #include.
$ То же, что и предыдущее, только относится к концу строки.
[СПИСОК] Означает любой символ из СПИСКА. Например, [aeiou] будет искать любую английскую гласную букву.
RE1\|RE2 Означает РВ1 или РВ2.
RE1RE2 Означает объединение регулярных выражений РВ1 и РВ2.
\n Означает символ новой строки.
Внимание: Остальные условные обозначения на основе обратного слэша (\), принятые в языке С, не поддерживаются программой sed.
\1 \2 \3 \4 \5 \6 \7 \8 \9 Означает соответствующую по счету часть регулярного выражения, запомненную при помощи знаков \( и \).
abcdef Означает abcdef
a*b Означает ноль или любое количество букв а и одна буква b. Например, aaaaaab; ab; или b.
a\?b Означает b или ab
a\+b\+ Означает одну или больше букв а и одну или больше букв b. Например: ab; aaaab; abbbbb; или aaaaaabbbbbbb.
.* Означает все символы на строке, на всех строках, включая пустые.
.\+ Означает все символы на строке, но только на строках, содержащих хотя бы один символ. Пустые строки не соответствуют данному регулярному выражению.
^main.*(.*) Будет искать строки, начинающиеся со слова main, а также имеющие в своем составе открывающую и закрывающие скобки, причем перед и после открывающей скобки может находиться любое количество символов (а может и не находиться).
^# Будет искать строки, начинающиеся со знака # (например комментарии).
\\$ Будет искать строки, заканчивающиеся обратным слэшем (\).
[a-zA-Z_] Любые буквы или цифры
^.*A.*$ Означает заглавную букву А точно в середине строки.
A.\<9\>$ Означает заглавную букву А, точно десятую по счету от конца строки.
^.\<,15\>A Означает заглавную букву А, точно шестнадцатую по счету от начала строки.
Теперь, когда мы познакомились с некоторыми регулярными выражениями, вернемся к команде s редактора sed.
Использование символа & когда ОБРАЗЕЦ неизвестен
Символ & (амперсанд), будучи помещен в состав ЗАМЕНЫ, означает любой найденный в тексте ОБРАЗЕЦ. Например:
Звездочка (астериск) после интервала 5 нужна чтобы заменены были все цифры, встретившиеся в образце. Без нее получилось бы:
То есть в качестве образца взята была первая же найденная цифра.
Вот пример со вполне осмысленной нагрузкой: составим файл formula.txt: и применим к нему команду:
Математическая формула приобрела однозначный смысл.
Еще символ амперсанда можно использовать для удвоения ОБРАЗЦА:
Тут есть одна тонкость. Если мы чуть усложним пример:
как и следовало ожидать, удваиваются только цифры, так как в ОБРАЗЦЕ нет букв. Но если мы поменяем части текста местами:
тогда цифры будут удваиваться, независимо от количества предшествующих «слов».
Использование условных знаков \(, \) и \1 для обработки части ОБРАЗЦА
Условные знаки \( и \) (escaped parentheses) применяются для запоминания части регулярного выражения.
Для того, чтобы поменять слова местами, нужно запомнить два суб-ОБРАЗЦА, а потом поменять их местами:
Знак \1 вовсе не обязан быть только в ЗАМЕНЕ, он может присутствовать также и в ОБРАЗЦЕ, например, когда мы хотим удалить дубликаты слов:
Модификаторы замены команды s
Модификатор /g
Программа sed, как и большинство утилит Юникс, при работе с файлами считывают по одной строке. Если мы приказываем заменить слово, программа заменит только первое совпавшее с ОБРАЗЦОМ слово на данной строке. Если мы хотим изменить каждое слово, совпавшее с образцом, то следует ввести модификатор /g.
Без модификатора /g:
Редактор заменил только первое совпавшее слово.
А теперь с модификатором глобальной замены:
Все совпадения в данной строке были заменены.
А если нужно изменить все слова, скажем взять их в скобки? Тогда на помощь снова придут регулярные выражения. Чтобы выбрать все буквенные символы, как верхнего, так и нижнего регистра, можно воспользоваться конструкцией [А-Яа-я], но в нее не попадут такие слова как «что-то» или «с’езд». Гораздо удобнее конструкция [^ ]*, которая соответствует всем символам, кроме пробела. Итак:
Как выбрать нужное совпадение из нескольких
В этом примере мы запомнили оба слова, и, поставив второе (пингвин) на первое место, первое (глупый) удалили, поставив в секции ЗАМЕНЫ вместо него пробел. Если мы поставим вместо пробела какое-либо слово, то оно заменит первое (глупый):
Числовой модификатор
В этом примере каждое слово является совпадением, и мы указали редактору, какое по счету слово мы хотим заменить, поставив модификатор 2 после секции ЗАМЕНЫ.
Можно комбинировать цифровой модификатор с модификатором /g. Если нужно оставить неизменным первое слово, а второе и последующие заменить на слово «(удалено)», то команда будет такая:
Если нужно действительно удалить все последующие совпадения, кроме первого, то в секции ЗАМЕНЫ следует поставить пробел:
Или вовсе ничего не ставить:
Числовой модификатор может быть любым целым числом от 1 до 512. Например, если нужно поставить двоеточие после 80 символа каждой строки, то поможет команда:
Модификатор /w
Модификатор /e (расширение GNU)
Модификаторы /I и /i (расширение GNU)
Комбинации модификаторов
Условные обозначения (расширение GNU)
По очевидным причинам эти условные обозначения применяются по одиночке. Например:
Мы рассмотрели почти все аспекты команды s редактора sed. Теперь настала очередь рассмотреть опции этой программы.
Опции программы sed
Назвать скрипт можно как угодно, важно не путать файл скрипта с обрабатываемым файлом.
Так как совпадений с ОБРАЗЦОМ не найдено (в файле нет цифр), то команда s с модификатором /p и знаком & в качестве ЗАМЕНЫ (напомню, что амперсанд означает сам ОБРАЗЕЦ), работает как команда cat.
Если ОБРАЗЕЦ будет найден в файле, то строки, содержащие ОБРАЗЕЦ, будут удвоены:
Выбор нужных элементов редактируемого текста
Программа sed умеет все это и даже больше. Любая команда редактора sed может применяться адресно, в некотором диапазоне адресов, или с вышеперечисленными ограничениями круга строк. Адрес или ограничение должны непосредственно предшествовать команде:
Выбор строк по номерам
Выбор строк в диапазоне номеров
Выбор строк, содержащих некое выражение
Выбор строк в диапазоне между двумя выражениями
Выбор строк от начала файла и до некоего выражения
Выбор строк от некоего выражения и до конца файла
Другие команды редактора sed
Команда d (delete)
Причем чаще пишут проще (без пробела):
Все, что было сказано в предыдущем разделе о адресации строк, справедливо и для команды d (как и для почти всех команд редактора sed).
При помощи команды d удобно выбросить ненужную «шапку» какого-нибудь почтового сообщения:
(Удалить строки с первой и до первой пустой строки).
Избавится от комментариев в конфигурационном файле:
И мало ли, где нужно удалить лишние строчки!
Команда p (print)
Будучи примененной сама по себе, команда p удваивает строки в выводе (ведь программа sed по умолчанию выводит строку на экран, а команда p выводит ту же строку вторично).
Этому свойству находится применение, например удвоить пустые строки для улучшения вида текста:
Например, просмотреть строки с первой по десятую:
Или только комментарии:
Или выберем все строки, кроме комментариев, из файла /boot/grub/menu.lst:
Команда q (quit)
Эта команда закончит работу по достижению 11-й строки.
Команда w (write)
Для работы в командной строке, удобнее пользоваться обычным перенаправлением вывода (> или >>), но в sed скриптах, вероятно, команда w найдет свое применение.
Команда r (read)
Команда =
Команда принимает только один адрес, не принимает интервалов.
Команда y
Команда y работает, только если количество символов в ОБРАЗЦЕ равно количеству символов в ЗАМЕНЕ.
Скрипты программы sed
Эта статья не может вместить описания скриптов sed, как и ее автор не ставит себе задачу освоение языка программирования sed. В этой статье я делал акцент на использование редактора sed в командной строке, имея прицел на использование его в качестве фильтра в программных каналах (pipes). По этой причине я опустил многочисленные команды sed, применяющиеся только в его скриптах.
Существует множество любителей редактора sed, и множество статей на тему скриптописания, в том числе и в Рунете. Так что для заинтересовавшихся этой замечательной программой не составит труда пополнить свои знания.
Программа sed и символы кириллицы
Резюме программы sed
Для освоения программы sed в полном объеме потребуются недели или даже месяцы работы, так как для этого необходимо:
С другой стороны, освоить несколько наиболее употребительных команд редактора sed не сложнее, чем любую команду Юникс; надеюсь, данная статья поможет вам в этом.
Послесловие
Данная статья является исключением, так как не описывает всех возможностей программы. Для полного их описания потребовалась бы не статья, а книга. Тем не менее, статья позволяет получить представление о редакторе sed и начать работать с этой удивительной программой, используя наиболее употребительные ее команды.